Programmierung
FileMaker meets Modern Dev Tools: FmClipTools + Raycast + VSCode
Wie Raycast-Integration repetitive Script-Bearbeitung beschleunigt und Fehler minimiert

Das Problem kennt jeder FileMaker-Entwickler
Stellen Sie sich folgendes Szenario vor: Sie entwickeln eine FileMaker-Lösung für einen Kunden und müssen Daten aus einer Katalog-Tabelle (T01_KATALOG) in eine Sortierdetails-Tabelle (_Sortierdetails) übertragen. Für jedes der 30 Produktfelder benötigen Sie einen identischen Script-Block, nur mit unterschiedlichen Feldnamen und Kategorien.
In FileMaker bedeutet das traditionell:
- Ersten Block manuell erstellen (6-8 Script-Schritte)
- Kopieren und 29× einfügen
- In jedem Block die Feldnamen einzeln ändern
- Kategoriewerte anpassen
- Hoffen, dass kein Tippfehler durchgerutscht ist
Zeitaufwand: Etwa 60 Minuten für 30 Felder
Fehlerquote: Hoch – Tippfehler bei POS_GELAENDER vs. POS_GELÄNDER passieren
FileMaker bietet keine Möglichkeit für Search & Replace über Script-Schritte hinweg. Die Script Workspace ist ein exzellentes Tool für die Script-Entwicklung, aber bei repetitiven Massenänderungen stößt sie an ihre Grenzen.
Die Lösung: Externe Tools für spezifische Aufgaben
Seit Jahren gibt es mit FmClipTools von Dan Shockley eine Lösung für dieses Problem. Das AppleScript-basierte Tool konvertiert FileMaker-Objekte (Scripts, Custom Functions, Layout-Objekte) von der Zwischenablage in bearbeitbares XML und zurück.
Das Konzept ist simpel:
- FileMaker-Objekte kopieren
- FmClipTools konvertiert zu XML
- XML in beliebigem Editor bearbeiten
- FmClipTools konvertiert zurück
- In FileMaker einfügen
Das funktioniert. Aber:
Der traditionelle Workflow mit FmClipTools erforderte Terminal-Befehle oder Navigation durch macOS Script-Menüs. Für gelegentliche Nutzung okay, für den täglichen Einsatz zu umständlich. Die mentale Barriere war hoch genug, dass ich FmClipTools nur bei wirklich großen Projekten einsetzte.
Dann kam Raycast.
Raycast: Der entscheidende Workflow-Beschleuniger
Raycast ist ein Launcher für macOS (ähnlich Alfred oder Spotlight, aber extensibler). Die Besonderheit: Man kann eigene Scripts als Commands einbinden, die per Tastatur-Shortcut aufrufbar sind.
Das klingt erst mal nach einer kleinen Optimierung. Aber der Unterschied in der Praxis ist erheblich.
Workflow-Vergleich
Ohne Raycast (traditionell):
1. FileMaker → Script Steps markieren und kopieren (Cmd+C)
2. Terminal öffnen oder Script-Menü aufrufen
3. FmClipTools-Befehl finden und ausführen
(osascript ~/Code/FmClipTools/Scripts/fmClip\ -\ Clipboard\ FM\ Objects\ to\ XML.applescript)
4. VSCode öffnen
5. Neue Datei erstellen
6. XML einfügen (Cmd+V)
7. Bearbeiten
8. XML kopieren (Cmd+A, Cmd+C)
9. Terminal/Script-Menü → Zurück-Konvertierung
10. FileMaker → Einfügen (Cmd+V)
Kontext-Wechsel: 5×
Kognitive Last: Terminal-Befehle merken, Pfade kennen
Zeit für Konvertierung: ~15-20 Sekunden pro Richtung
Mit Raycast:
1. FileMaker → Script Steps markieren und kopieren (Cmd+C)
2. Raycast öffnen (Cmd+Space)
3. Tippen: "fm to" → Enter
4. VSCode → XML einfügen, bearbeiten
5. XML kopieren (Cmd+A, Cmd+C)
6. Raycast öffnen (Cmd+Space)
7. Tippen: "xml to" → Enter
8. FileMaker → Einfügen (Cmd+V)
Kontext-Wechsel: 2×
Kognitive Last: Zwei einfache Befehle
Zeit für Konvertierung: ~3 Sekunden pro Richtung
Der eigentliche Unterschied
Es geht nicht um die gesparten 10 Sekunden. Es geht um Reibungslosigkeit.
Mit Raycast wird FmClipTools vom “mächtigen Spezial-Tool für große Projekte” zum alltäglichen Workflow-Baustein. Die mentale Schwelle, das Tool einzusetzen, verschwindet.
Vorher dachte ich: “Lohnt sich der Aufwand für nur 5 Felder?”
Heute denke ich: “Cmd+Space, fm to, Enter – fertig.”
Das ist der Unterschied zwischen einem Tool, das man kennt, und einem Tool, das man tatsächlich nutzt.
Die Komponenten im Detail
FmClipTools: Das Fundament
GitHub: DanShockley/FmClipTools
FmClipTools ist ein AppleScript-basiertes Toolset von Dan Shockley. Es konvertiert FileMaker-Clipboard-Objekte in XML und zurück.
Was es kann:
- Script Steps ↔ XML
- Custom Functions ↔ XML
- Layout Objects ↔ XML
- Fields/Tables ↔ XML
- Value Lists ↔ XML
- Themes ↔ XML
Was wichtig ist:
- Seit Jahren bewährt
- Aktiv maintained (letzte Updates August 2025 für FileMaker Pro 2025)
- Open Source (MIT License)
- Einschränkung: Nur macOS (AppleScript-Basis)
VSCode: Der Editor
Visual Studio Code ist meine IDE der Wahl für Code-Arbeit. Für FileMaker-XML bietet VSCode:
Relevante Features:
- Search & Replace mit Regex
- Multi-Cursor für parallele Änderungen
- XML Tools Extension (automatisches Formatieren)
- Git-Integration (XML-Dateien versionierbar)
Konkret nützlich:
// Regex Replace: Alle Tabellenreferenzen ändern
Suchen (Regex): table="T01_KATALOG" id="(\d+)" name="([^"]+)"
Ersetzen: table="T02_ARTIKEL" id="$1" name="$2"
Oder Multi-Cursor:
1. Cmd+F → "T01_KATALOG" suchen
2. Cmd+Shift+L → Alle Vorkommen markieren
3. Direkt tippen: "T02_ARTIKEL"
→ Alle 47 Vorkommen gleichzeitig geändert
Das geht in FileMaker schlicht nicht.
Extension-Empfehlung:
- XML Tools (Josh Johnson)
Installation:
code --install-extension DotJoshJohnson.xml
Raycast: Der Klebstoff
Raycast ist ein Launcher für macOS. Relevant für diesen Workflow:
Script Commands:
Man kann Shell-Scripts als Raycast-Commands registrieren. Diese werden dann:
- Per Tastatur auffindbar (fuzzy search)
- Sofort ausführbar
- Im Hintergrund laufend (silent mode)
Setup für FmClipTools:
Drei kleine Wrapper-Scripts in:
~/Library/Application Support/Raycast/Script Commands/FmClipTools/
Script 1: fm-to-xml.sh
#!/bin/bash
# Required parameters:
# @raycast.schemaVersion 1
# @raycast.title FM → XML
# @raycast.mode silent
# @raycast.packageName FmClipTools
# Optional parameters:
# @raycast.icon 📋
# @raycast.description Convert FileMaker Clipboard to XML
osascript "$HOME/Code/FmClipTools/Scripts/fmClip - Clipboard FM Objects to XML.applescript"
Script 2: xml-to-fm.sh
#!/bin/bash
# Required parameters:
# @raycast.schemaVersion 1
# @raycast.title XML → FM
# @raycast.mode silent
# @raycast.packageName FmClipTools
# Optional parameters:
# @raycast.icon 📝
# @raycast.description Convert XML to FileMaker Clipboard
osascript "$HOME/Code/FmClipTools/Scripts/fmClip - Clipboard XML to FM Objects.applescript"
Ausführbar machen:
chmod +x ~/Library/Application\ Support/Raycast/Script\ Commands/FmClipTools/*.sh
Nutzung:
Cmd+Space→fm to→ EnterCmd+Space→xml to→ Enter
Das war’s. Keine Menüs, keine Pfade, keine Befehle merken.
Und das Beste, es geht auch z.B. über Cursor vollständig autonom. Statt die Kommandos händisch abzusetzen, ein aussagekräftigen Prompt und alle Schritte werden durch z.B. Sonnet 4.5. eigenständig durchgeführt.
Praktisches Beispiel: 30 Felder in 25 Minuten
Ausgangslage
Kunde benötigt Script zur Datenübertragung von T01_KATALOG zu _Sortierdetails.
Für jedes Produktfeld (POS_HL, POS_BLENDEN, POS_STUETZEN, etc.) soll geprüft werden:
- Ist das Feld in
T01_KATALOGbefüllt? - Falls ja: Neuen Datensatz in
_Sortierdetailserstellen - Kategorie setzen (“Handlauf”, “Blenden”, etc.)
- Menge übertragen
Ein Block sieht so aus (in FileMaker):
Wenn [ NICHT IstLeer ( T01_KATALOG::POS_HL ) ]
Gehe zu Layout [ "tabelle_sortierdetails" ]
Neuer Datensatz/Abfrage
Feldwert setzen [ _Sortierdetails::t_bereich ; "Handlauf" ]
Feldwert setzen [ _Sortierdetails::t_kategorie ; "Geländer" ]
Feldwert setzen [ _Sortierdetails::Menge ; T01_KATALOG::POS_HL ]
Ende (wenn)
Das sind 7 Script-Schritte pro Feld × 30 Felder = 210 Script-Schritte.
Schritt 1: Basis-Block erstellen und kopieren
In FileMaker: Ersten Block für POS_HL manuell erstellen.
Script Steps markieren → Cmd+C
Schritt 2: Zu XML konvertieren
Raycast → Cmd+Space
Tippe: "fm to"
Enter
Zwischenablage enthält jetzt XML.
Schritt 3: In VSCode einfügen
VSCode → Cmd+N (neue Datei)
Cmd+V (einfügen)
Shift+Alt+F (XML formatieren)
Cmd+S → "katalog_to_sortierdetails.xml"
Das XML sieht so aus:
<?xml version="1.0" encoding="UTF-8"?>
<fmxmlsnippet type="FMObjectList">
<Step enable="True" id="68" name="Wenn">
<Restore state="False"></Restore>
<Calculation><![CDATA[NICHT IstLeer (T01_KATALOG::POS_HL)]]></Calculation>
</Step>
<Step enable="True" id="6" name="Gehe zu Layout">
<Restore state="False"></Restore>
<LayoutDestination value="SelectedLayout"></LayoutDestination>
<Layout id="40" name="tabelle_sortierdetails"></Layout>
</Step>
<Step enable="True" id="7" name="Neuer Datensatz/Abfrage">
<Restore state="False"></Restore>
</Step>
<Step enable="True" id="76" name="Feldwert setzen">
<Restore state="False"></Restore>
<Repetition value="1"></Repetition>
<Field table="_Sortierdetails" id="52" name="t_bereich"></Field>
<Calculation><![CDATA["Handlauf"]]></Calculation>
</Step>
<Step enable="True" id="76" name="Feldwert setzen">
<Restore state="False"></Restore>
<Repetition value="1"></Repetition>
<Field table="_Sortierdetails" id="53" name="t_kategorie"></Field>
<Calculation><![CDATA["Geländer"]]></Calculation>
</Step>
<Step enable="True" id="76" name="Feldwert setzen">
<Restore state="False"></Restore>
<Repetition value="1"></Repetition>
<Field table="_Sortierdetails" id="66" name="Menge"></Field>
<Calculation><![CDATA[T01_KATALOG::POS_HL]]></Calculation>
</Step>
<Step enable="True" id="70" name="Ende (wenn)">
</Step>
</fmxmlsnippet>
Schritt 4: Block duplizieren und anpassen
Block kopieren:
1. Zeilen 3-26 markieren (der gesamte Block)
2. Cmd+C
3. Cursor unter Block setzen
4. Cmd+V (29× wiederholen für insgesamt 30 Blöcke)
Pro Block anpassen (Beispiel für POS_BLENDEN):
Cmd+H (Find & Replace)
Suchen: POS_HL
Ersetzen: POS_BLENDEN
→ Replace All (in aktuellem Block)
Suchen: "Handlauf"
Ersetzen: "Blenden"
→ Replace All
Für 30 Felder: ~20 Minuten mit Copy-Paste + Replace.
Alternative für Fortgeschrittene:
Liste der Feldnamen in separater Datei → Python/Shell-Script generiert alle 30 Blöcke automatisch.
Schritt 5: Zurück zu FileMaker
VSCode: Cmd+A → Cmd+C (gesamtes XML kopieren)
Raycast: Cmd+Space → "xml to" → Enter
FileMaker: Script Workspace → Cmd+V
Fertig.
210 Script-Schritte sind jetzt im Script. Alle korrekt, keine Tippfehler.
Zeitvergleich
Manuell in FileMaker:
- Ersten Block erstellen: 5 Minuten
- 29× kopieren und anpassen: ~55 Minuten
- Gesamt: ~60 Minuten
- Fehlerquote: 2-3 Tippfehler wahrscheinlich
Mit FmClipTools + Raycast + VSCode:
- Ersten Block erstellen: 5 Minuten
- XML-Export: 10 Sekunden
- 29× duplizieren und anpassen in VSCode: ~15 Minuten
- XML-Import: 10 Sekunden
- Gesamt: ~25 Minuten
- Fehlerquote: ~0% (Regex statt Handarbeit)
Zeitersparnis: 35 Minuten = 58%
Und das bei deutlich geringerer Fehlerquote.
Wann lohnt sich der Workflow?
Sinnvoll bei:
Repetitive Script-Blöcke:
- Mehr als 5 ähnliche Blöcke
- Template-basierte Generierung
- Massenänderungen an bestehenden Scripts
Tabellen-/Feldnamen ändern:
- Refactoring nach Datenmodell-Änderung
- Kunde ändert Namenskonventionen
- Mehrsprachige Lösungen anpassen
Dokumentation:
- XML-Dateien in Git versionierbar
- Diff zeigt Script-Änderungen sauber
- Code-Reviews außerhalb von FileMaker möglich
Overhead bei:
Kleine Änderungen:
- Einzelne Script-Schritte anpassen
- Ad-hoc Script-Entwicklung
- Wenn ohnehin in FileMaker Script Workspace
Windows-Umgebung:
- FmClipTools ist macOS-only
- Keine Alternative mit vergleichbarer Qualität bekannt
Gelegentliche Nutzung:
- Setup-Zeit amortisiert sich erst ab regelmäßigem Einsatz
- Lernkurve: 2-3 Anwendungen bis Workflow sitzt
Setup-Anleitung
Voraussetzungen
- macOS (FmClipTools basiert auf AppleScript)
- FileMaker Pro (getestet mit FM 19-2025)
- Raycast (kostenlose Version reicht)
- VSCode (oder anderer XML-fähiger Editor)
Zeitaufwand: 15-20 Minuten einmalig
Schritt 1: FmClipTools installieren
# Ordner erstellen
mkdir -p ~/Code
# Repository klonen
cd ~/Code
git clone https://github.com/DanShockley/FmClipTools.git
# Testen
osascript ~/Code/FmClipTools/Scripts/fmClip\ -\ Clipboard\ FM\ Objects\ to\ XML.applescript
Wenn keine Fehlermeldung kommt: Installation erfolgreich
Schritt 2: VSCode vorbereiten
# XML Tools Extension installieren
code --install-extension DotJoshJohnson.xml
Optional: FileMaker VSCode Extension für Syntax-Highlighting bei Calculations:
code --install-extension jwillinghalpern.filemaker-vscode
Schritt 3: Raycast einrichten
Raycast installieren:
# Via Homebrew
brew install --cask raycast
# Oder von https://www.raycast.com herunterladen
Script Commands Ordner erstellen:
mkdir -p ~/Library/Application\ Support/Raycast/Script\ Commands/FmClipTools
Wrapper-Scripts erstellen:
Datei: ~/Library/Application Support/Raycast/Script Commands/FmClipTools/fm-to-xml.sh
#!/bin/bash
# Required parameters:
# @raycast.schemaVersion 1
# @raycast.title FM → XML
# @raycast.mode silent
# @raycast.packageName FmClipTools
# @raycast.icon 📋
# @raycast.description Convert FileMaker Clipboard to XML
osascript "$HOME/Code/FmClipTools/Scripts/fmClip - Clipboard FM Objects to XML.applescript"
Datei: ~/Library/Application Support/Raycast/Script Commands/FmClipTools/xml-to-fm.sh
#!/bin/bash
# Required parameters:
# @raycast.schemaVersion 1
# @raycast.title XML → FM
# @raycast.mode silent
# @raycast.packageName FmClipTools
# @raycast.icon 📝
# @raycast.description Convert XML to FileMaker Clipboard
osascript "$HOME/Code/FmClipTools/Scripts/fmClip - Clipboard XML to FM Objects.applescript"
Ausführbar machen:
chmod +x ~/Library/Application\ Support/Raycast/Script\ Commands/FmClipTools/*.sh
Raycast neu starten:
killall Raycast && open -a Raycast
Testen:
Cmd+Space → "fm" tippen
→ Sollte "FM → XML" und "XML → FM" zeigen
Schritt 4: Ersten Test durchführen
- In FileMaker: Mini-Script erstellen (3-5 Steps)
- Script Steps kopieren: Cmd+C
- Raycast: Cmd+Space → “fm to” → Enter
- VSCode: Neue Datei → Cmd+V → Shift+Alt+F
- Etwas ändern: z.B. Feldname
- Kopieren: Cmd+A → Cmd+C
- Raycast: Cmd+Space → “xml to” → Enter
- FileMaker: Neues Script → Cmd+V
Wenn die geänderten Script-Schritte korrekt eingefügt werden: Setup vollständig!
Erfahrungswerte nach 30 Tagen Praxiseinsatz
Einsatz-Häufigkeit
Meine Nutzung (FileMaker-Vollzeit-Entwickler):
- 3-4× pro Woche bei größeren Projekten
- 1-2× pro Woche bei Wartung/Refactoring
- Hauptsächlich: Script-Template-Duplikation, Massenänderungen
Typische Use-Cases:
- Katalog-Import-Scripts (20-40 Felder)
- Berechtigungssysteme (ähnliche Scripts pro Rolle)
- Refactoring nach Datenmodell-Änderungen
Zeitersparnis
Pro Einsatz:
- Bei 10-20 Feldern: ~15-20 Minuten gespart
- Bei 30+ Feldern: ~30-40 Minuten gespart
- Pro Monat: ca. 2-3 Stunden
Wichtiger als Zeitersparnis:
- Fehlerrate massiv reduziert
- Mentale Last geringer (kein monotones Copy-Paste)
- Dokumentation als Nebeneffekt (XML-Dateien)
Fehlerreduktion
Messbar weniger Fehler bei:
- Tippfehler in Feldnamen: -90%
- Vergessene Anpassungen: -95%
- Falsche Layout-Referenzen: -100% (Regex findet alle)
Beispiel:
Vorher: Bei 30 Feldern durchschnittlich 2-3 Fehler, die beim Testen auffielen.
Jetzt: 0 Fehler durch Search & Replace.
Nicht erwartete Vorteile
Git-Integration:
- XML-Dateien versionierbar
- Script-Änderungen in Git-Diff sichtbar
- Code-Reviews möglich (ohne FileMaker zu öffnen)
Dokumentation:
- XML ist menschenlesbar
- Kann als Script-Dokumentation dienen
- Einfacher zu archivieren als Screenshots
Template-Bibliothek:
- Häufige Script-Muster als XML-Templates
- Wiederverwendbar über Projekte hinweg
- Schneller als FileMaker Copy-Paste zwischen Dateien
Einschränkungen und wichtige Hinweise
Technische Einschränkungen
Nur macOS:
- FmClipTools basiert auf AppleScript
- Keine Windows-Alternative bekannt
- Parallels/VM funktioniert, aber umständlich
FileMaker-IDs bleiben erhalten:
- Script-Step-IDs, Field-IDs, Layout-IDs werden nicht neu generiert
- Bei Copy-Paste zwischen Dateien kann das Probleme machen
- Lösung: XML manuell anpassen oder FmClipTools-Variante nutzen
Nicht alle FileMaker-Objekte:
- Custom Functions: Funktioniert, aber eingeschränkt bearbeitbar
- Wertelisten: Funktioniert
- Scripts: Perfekt
- Themes: Funktioniert (seit 2023)
Workflow-Einschränkungen
Lernkurve:
- Erste 1-2 Anwendungen: Unsicherheit
- Nach 3-4 Anwendungen: Workflow sitzt
- XML-Kenntnisse hilfreich, aber nicht zwingend
Raycast-Kosten:
- Free Version: Völlig ausreichend
- Pro Version: €8/Monat (wenn man Raycast intensiv nutzt)
- Alternative: Alfred Powerpack (~€25 einmalig)
Fehlerquellen:
Selbstschließende Tags funktionieren NICHT:
<!-- FALSCH (FileMaker erkennt es nicht): -->
<Restore state="False"/>
<!-- RICHTIG: -->
<Restore state="False"></Restore>
Mehrere <fmxmlsnippet> Blöcke in einer Datei:
- Nur EIN Block pro Konvertierung!
- Bei mehreren: Nur erster wird konvertiert
Wann NICHT verwenden
Bei einzelnen kleinen Änderungen:
- Overhead lohnt sich nicht
- FileMaker Script Workspace schneller
Bei komplexen Berechnungen:
- FileMaker Data Viewer besser zum Testen
- Calculation Dialog zeigt Fehler direkt
Bei Layout-Design:
- Layout-Objekte sind in XML schwer zu visualisieren
- Besser direkt in FileMaker
Weiterführende Möglichkeiten
Python-Script-Generierung
Für wirklich große Projekte (50+ ähnliche Blöcke):
# generate_fm_scripts.py
import xml.etree.ElementTree as ET
fields = [
("POS_HL", "Handlauf"),
("POS_BLENDEN", "Blenden"),
# ... 50 weitere
]
template = """<Step enable="True" id="68" name="Wenn">
<Calculation><![CDATA[NICHT IstLeer (T01_KATALOG::{field})]]></Calculation>
</Step>"""
for field, category in fields:
print(template.format(field=field, category=category))
Kombiniert mit FmClipTools: Generierung in Sekunden.
Git-basierter Workflow
Scripts als XML in Git:
# FileMaker-Projekt mit Git-Repo
~/Projects/CustomerDB/
├── database/
│ └── customer.fmp12
└── scripts/
├── import_catalog.xml
├── export_reports.xml
└── automation/
└── nightly_backup.xml
# Workflow:
1. Script in FileMaker entwickeln
2. FmClipTools → XML exportieren
3. Git commit mit Beschreibung
4. Bei Bedarf: XML → FmClipTools → FileMaker reimportieren
Vorteil: Script-Historie außerhalb von FileMaker.
Team-Workflows
Code-Reviews ohne FileMaker:
# Kollege schickt Pull Request mit Script-Änderungen
git diff scripts/import_catalog.xml
# Zeigt genau was geändert wurde:
- <Field table="T01_KATALOG" name="alte_bezeichnung">
+ <Field table="T01_KATALOG" name="neue_bezeichnung">
Review im Browser, ohne FileMaker zu öffnen.
Template-Bibliothek
Häufige Script-Muster als Snippets:
~/FileMaker-Templates/
├── if-field-not-empty.xml
├── create-related-record.xml
├── export-to-excel.xml
└── send-email-with-attachment.xml
Bei Bedarf: Template laden → anpassen → importieren.
Alternative Ansätze
Für Windows-Nutzer
Clipboard Explorer (2empowerFM):
- Kommerziell (~€30)
- Ähnliche Funktionalität wie FmClipTools
- Weniger aktiv maintained
BaseElements Plugin:
- Free FileMaker Plugin
- Kann Script-XML exportieren
- Kein direktes Clipboard-Handling
Für Terminal-Affine
FmClipTools direkt via Shell-Aliases:
# ~/.zshrc
alias fm2xml="osascript ~/Code/FmClipTools/Scripts/fmClip\ -\ Clipboard\ FM\ Objects\ to\ XML.applescript"
alias xml2fm="osascript ~/Code/FmClipTools/Scripts/fmClip\ -\ Clipboard\ XML\ to\ FM\ Objects.applescript"
# Nutzung:
fm2xml # statt Raycast
Schneller als Raycast für Terminal-Nutzer.
Für Alfred-Nutzer
Alfred Workflows mit gleicher Funktionalität erstellbar:
Keyword: "fm2xml" → Run Script → osascript ...
Keyword: "xml2fm" → Run Script → osascript ...
Raycast hat aber bessere Script-Command-Integration.
Fazit
Raycast macht den Unterschied
FmClipTools existiert seit Jahren und ist ein ausgezeichnetes Werkzeug. Aber erst mit Raycast wird es zum alltäglichen Workflow-Baustein.
Der Zeitgewinn kommt nicht primär vom XML-Editing (das ging vorher auch), sondern von der Reibungslosigkeit des Prozesses.
Keine Terminal-Befehle. Keine Menü-Navigation. Keine Pfade merken.
Nur: Cmd+Space → drei Buchstaben → Enter.
Das ist der Unterschied zwischen “kenne ich” und “nutze ich täglich”.
Für wen geeignet?
Definitiv für:
- FileMaker-Entwickler mit repetitiven Script-Aufgaben
- Teams, die Script-Dokumentation außerhalb von FM wollen
- Refactoring-intensive Projekte
- macOS-Nutzer
Eher nicht für:
- Gelegentliche FileMaker-Nutzer
- Windows-Entwickler (mangels FmClipTools)
- Wer Terminal-Workflows bevorzugt (Raycast dann unnötig)
Persönliche Empfehlung
Nach 2 Tagen intensiver Nutzung: Klare Empfehlung.
Die 20 Minuten Setup-Zeit haben sich bereits nach der zweiten Anwendung amortisiert. Die Fehlerreduktion allein wäre es wert, die Zeitersparnis ist Bonus.
Ein Tool zum Arbeiten.
Downloads und Ressourcen
Software
- FmClipTools: https://github.com/DanShockley/FmClipTools
- Raycast: https://www.raycast.com
- VSCode: https://code.visualstudio.com
- XML Tools Extension: https://marketplace.visualstudio.com/items?itemName=DotJoshJohnson.xml
Weiterführende Links
- Dan Shockley’s Blog: https://www.danshockley.com
- Raycast Script Commands: https://github.com/raycast/script-commands
Der 70-Tabellen Wahnsinn: Eine Kontaktdatenbank im Normalisierungs-Rausch
Oder: Wie man aus einer simplen Adressverwaltung ein akademisches Meisterwerk der Über-Architektur erschafft*

Ein gefährliches Gedankenspiel
Heute Morgen saß ich am Schreibtisch, starrte auf meine FileMaker-Lösung und dachte mir: “Wäre es nicht herrlich, einmal komplett durchzudrehen?” Nicht im Sinne von schlechtem Code oder wilden Skripten, sondern im Sinne von theoretischer Perfektion. Von akademischer Reinheit. Von Normalisierung, die so weit geht, dass selbst Edgar F. Codd sich im Grab umdreht und fragt: “Habe ich das wirklich so gemeint?”
Heute nehme ich euch mit auf eine Reise in die dunkle Seite der Datenbankentwicklung. Wir werden gemeinsam eine Kontaktdatenbank bauen, die so übernormalisiert ist, dass sie in der Praxis völlig unbrauchbar wäre. Wir sprechen von siebzig Tabellen. Siebzig! Für Kontakte, Adressen und ein bisschen Drumherum. Das ist ungefähr so, als würde man einen Nagel mit einem Vorschlaghammer einschlagen, während man auf einem Einrad balanciert und dabei Schach spielt.
Vorweg: Das solltet ihr niemals tun. Aber es macht wahnsinnig viel Spaß, und man lernt dabei eine Menge über Normalisierung, Beziehungen und darüber, wann genug wirklich genug ist.
Die Ausgangslage: Eine ganz normale Kontaktdatenbank
Stellen wir uns vor, wir wollen eine Kontaktdatenbank bauen. Nichts Wildes. Einfach Namen, Adressen, Telefonnummern, E-Mails. Das Zeug, das jeder braucht. In der Praxis würde man vielleicht mit drei, vier Tabellen davonkommen. Kontakte, Adressen, Telefonnummern, E-Mails. Fertig. Schön übersichtlich, performant, wartbar.
Aber wo bleibt da der Spaß? Wo ist die theoretische Eleganz? Wo sind die Normalformen, von denen alle reden, die aber keiner wirklich konsequent durchzieht? Genau hier fängt unser Abenteuer an.
Der Plan: Maximale Normalisierung
Die Idee ist simpel: Wir normalisieren alles, was nicht bei drei auf den Bäumen ist. Jede noch so kleine Information bekommt ihre eigene Tabelle. Jede Redundanz wird gejagt und eliminiert. Jede transitive Abhängigkeit wird aufgelöst. Wir gehen nicht nur bis zur dritten Normalform, nicht mal bis zur BCNF. Wir gehen bis zur fünften, vielleicht sogar sechsten Normalform, wenn wir wirklich übermütig werden.
Das Ergebnis? Eine Datenbank-Struktur, die aussieht wie ein Spinnennetz nach einem Tornado. Oder wie der Stammbaum der britischen Königsfamilie. Oder wie mein Schreibtisch nach einer langen Entwicklungssession.
Die Kontakte: Wo alles beginnt
Fangen wir harmlos an. Ein Kontakt hat einen Vornamen, einen Nachnamen, vielleicht ein Geburtsdatum. In einer normalen Welt würden wir das in eine Tabelle schreiben und fertig. Aber wir sind ja nicht normal.
Ein Kontakt hat eine Anrede. Herr, Frau, Divers. Das kann sich ändern. Das muss zentral verwaltet werden. Also brauchen wir eine Anreden-Tabelle. Klingt noch vernünftig, oder? Gut, dann machen wir weiter.
Ein Kontakt kann einen Titel haben. Dr., Prof., Dipl.-Ing. und all die schönen Dinge, mit denen Menschen sich schmücken. Aber hier wird es spannend: Manche Titel stehen vor dem Namen, manche danach. In Deutschland sagt man “Dr. Müller”, in Österreich manchmal “Müller, Dr.”. Das ist eine Information! Eine strukturierte Information! Also brauchen wir nicht nur eine Titel-Tabelle, sondern auch eine TitelPositionen-Tabelle. Zwei Tabellen, nur damit wir wissen, ob der Doktortitel vor oder nach dem Namen kommt. Herrlich übertrieben, oder?
Die Firmen: Ein Exkurs in die Unternehmensarchitektur
Kontakte arbeiten in Firmen. Das ist nichts Neues. Aber eine Firma ist nicht einfach nur ein Name. Eine Firma hat eine Rechtsform. GmbH, AG, e.K., OHG, KG, und was weiß ich noch alles. Die Rechtsform sagt etwas über die Struktur aus, über Haftung, über steuerliche Behandlung. Das ist wichtig! Also brauchen wir eine Rechtsformen-Tabelle.
Und dann ist da noch die Branche. IT, Maschinenbau, Einzelhandel, Gastronomie. Branchen ändern sich, Branchen haben Hierarchien, Branchen sind komplex. Also brauchen wir eine Branchen-Tabelle. Vielleicht sogar mit Hierarchien, aber das würde jetzt zu weit führen. Wir haben ja erst bei Tabelle Nummer acht oder so.
Und weil ein Kontakt bei mehreren Firmen arbeiten kann, gleichzeitig oder nacheinander, brauchen wir natürlich eine Verknüpfungstabelle. Kontakt_Firma. Mit Position (Geschäftsführer, Angestellter, Freelancer), mit von-Datum und bis-Datum für die Historisierung. Und die Position? Rate mal. Eigene Tabelle. Positionen-Tabelle. Weil sich Positionsbezeichnungen ändern können und wir sie zentral verwalten wollen.
Die Adressen: Ein geografisches Meisterwerk
Jetzt wird es richtig lustig. Adressen sind kompliziert. Wirklich kompliziert. Eine Adresse besteht aus einer Straße, einer Hausnummer, einer Postleitzahl, einem Ort, einem Land. Das würde die meisten zufriedenstellen. Aber nicht uns. Oh nein.
Fangen wir mit der Straße an. Eine Straße hat einen Namen. Aber eine Straße gehört zu einem Ort. Und verschiedene Orte können Straßen mit dem gleichen Namen haben. Die Hauptstraße in Berlin ist nicht die Hauptstraße in München. Also brauchen wir eine Strassen-Tabelle, die zu einem Ort gehört. Schon haben wir eine Redundanz eliminiert.
Die Postleitzahl? Die gehört zur Adresse, nicht zum Ort! Ein großer Ort kann mehrere Postleitzahlen haben. Berlin hat hunderte davon. Also brauchen wir eine PLZ-Tabelle, die wiederum zu einem Ort gehört. Moment, aber eine PLZ kann sich auch über mehrere Orte erstrecken? Stimmt! Also machen wir eine n:m-Beziehung daraus. Ups, schon wieder komplizierter.
Orte gehören zu Regionen. Bundesländer, Kantone, Staaten, je nachdem wo wir sind. Also Regionen-Tabelle. Und Regionen gehören zu Ländern. Also Länder-Tabelle. Und Länder haben ISO-Codes, zweibuchstabig und dreibuchstabig, und Ländervorwahlen für Telefonnummern. Und eine Währung! Also brauchen wir auch noch eine Währungen-Tabelle.
Ach, und ich habe fast die Adresszusätze vergessen. “c/o”, “bei”, “℅”. Das sind strukturierte Informationen! Adresszusätze-Tabelle. Und natürlich brauchen wir eine AdressTypen-Tabelle, denn eine Adresse kann privat, geschäftlich, eine Lieferadresse oder eine Rechnungsadresse sein.
Und weil sowohl Kontakte als auch Firmen mehrere Adressen haben können, brauchen wir Verknüpfungstabellen. Kontakt_Adresse und Firma_Adresse. Mit einem Flag, welche die Hauptadresse ist. Und mit Gültigkeitsdaten, denn Menschen und Firmen ziehen um.
Wir sind jetzt bei ungefähr zwanzig Tabellen. Nur für Kontakte, Firmen und Adressen. Und wir haben noch nicht einmal über Telefonnummern gesprochen.
Die Telefonnummern: Eine Ode an die Verkomplizierung
Telefonnummern sind toll. Man könnte sie einfach als String speichern und gut ist. Aber wo bleibt da die Struktur? Wo ist die Eleganz?
Eine Telefonnummer besteht aus einer Ländervorwahl, einer Ortsvorwahl, einer Rufnummer und vielleicht einer Durchwahl. Das sind vier Felder! Vier strukturierte Informationen! Also brauchen wir eine Telefonnummern-Tabelle mit all diesen Feldern.
Aber die Ländervorwahl? Die gehört zu einem Land! Also brauchen wir eine Ländervorwahlen-Tabelle, die zur Länder-Tabelle verlinkt. Ja, wir haben die Ländervorwahl schon in der Länder-Tabelle gespeichert, aber das wäre ja eine Redundanz! Also machen wir eine eigene Tabelle daraus, damit wir sauber bleiben.
Und dann ist da noch der Typ. Mobil, Festnetz, Fax, VoIP. Das sind strukturierte Kategorien. TelefonTypen-Tabelle. Natürlich.
Und weil wieder sowohl Kontakte als auch Firmen Telefonnummern haben können, brauchen wir Verknüpfungstabellen. Kontakt_Telefon und Firma_Telefon. Mit einem Flag für die Hauptnummer. Mit Gültigkeitsdaten. Ihr kennt das Spiel.
E-Mails, Websites und der Rest: Wir sind noch nicht fertig
E-Mail-Adressen? Eigene Tabelle. Mit einem EmailTyp (privat, geschäftlich, Newsletter). EmailTypen-Tabelle. Und wieder Verknüpfungstabellen für Kontakte und Firmen. Kontakt_Email, Firma_Email.
Websites? Eigene Tabelle. Mit einem WebsiteTyp (Hauptwebsite, Blog, LinkedIn, XING, Facebook, Instagram, TikTok, was auch immer). WebsiteTypen-Tabelle. Und wieder Verknüpfungstabellen. Ihr ahnt es schon.
Bankverbindungen? IBAN, BIC, und eine Referenz zur Bank. Und die Bank? Eigene Tabelle natürlich! Mit Bankname, BLZ und einer Referenz zum Land. Und wieder Verknüpfungstabellen für Kontakte und Firmen.
Steuer-IDs? Eigene Tabelle! Mit einem SteuerTyp (USt-ID, Steuernummer, UID, je nach Land). SteuerTypen-Tabelle. Die wiederum eine Referenz zum Land hat, weil verschiedene Länder verschiedene Steuertypen haben. Und wieder Verknüpfungstabellen.
Wir sind jetzt irgendwo bei vierzig, fünfzig Tabellen. Und ich habe noch ein paar Ideen.
Die Kür: Beziehungen, Sprachen und Tags
Kontakte haben Beziehungen zueinander. Ehepartner, Kinder, Geschwister, Geschäftspartner, Freunde. Das ist eine klassische n:m-Beziehung. Also brauchen wir eine Beziehungen-Tabelle, die zwei Kontakte miteinander verbindet. Und natürlich einen BeziehungsTyp. BeziehungsTypen-Tabelle. Mit einem Datum, seit wann die Beziehung besteht. Man will ja dokumentieren, wann man geheiratet hat oder wann die Geschäftsbeziehung begann.
Kontakte sprechen Sprachen. Und Firmen kommunizieren in Sprachen. Also brauchen wir eine Kommunikationssprachen-Tabelle, die entweder zu einem Kontakt oder zu einer Firma gehört. Und diese Tabelle verweist auf eine Sprachen-Tabelle mit dem Sprachennamen und ISO-Code. Und auf eine Sprachlevel-Tabelle (Muttersprache, Fließend, Grundkenntnisse), weil das Level der Sprachkenntnisse relevant ist.
Und dann sind da noch Tags. Kategorien. Labels. Wie auch immer man sie nennen will. Kontakte und Firmen können mit Tags versehen werden, um sie zu gruppieren, zu filtern, zu organisieren. Also brauchen wir eine Tags-Tabelle. Und weil Tags selbst wieder Kategorien haben können (Marketing-Tags, Projekt-Tags, Status-Tags), brauchen wir eine TagKategorien-Tabelle. Und natürlich Verknüpfungstabellen. Kontakt_Tag und Firma_Tag.
Jetzt sind wir bei siebzig Tabellen. Siebzig! Für eine Kontaktdatenbank!
Das Diagramm: Visuelle Überforderung garantiert
An dieser Stelle sollte ich eigentlich ein Diagramm zeigen, das all diese Tabellen und ihre Beziehungen visualisiert. Aber ehrlich gesagt, das würde diesen Blog-Post sprengen. Ich habe das Diagramm erstellt. Es ist ein Monster. Es sieht aus wie ein Spinnennetz auf Steroiden. Es hat mehr Linien als ein U-Bahn-Plan von Tokio. Es ist wunderschön und schrecklich zugleich.
Wenn ihr das Diagramm sehen wollt, könnt ihr es euch als Mermaid-Datei herunterladen und in einem Tool eurer Wahl anschauen. Ich empfehle mermaid.live, denn dann könnt ihr ordentlich hinein- und herauszoomen. Ihr werdet es brauchen. Glaubt mir.
Das Diagramm zeigt jede einzelne Tabelle mit ihren Attributen, ihren Primary Keys, ihren Foreign Keys. Es zeigt jede Beziehung, jede Kardinalität, jeden Join. Es ist ein akademisches Meisterwerk. Und es ist in der Praxis völlig wahnsinnig.
Die Realität: Warum niemand das tun sollte
Jetzt fragt ihr euch wahrscheinlich: “Warum zum Teufel erzählst du uns das alles, wenn es doch sowieso niemand machen sollte?” Gute Frage. Die Antwort ist zweiteilig.
Erstens: Weil es wichtig ist zu verstehen, wie weit Normalisierung theoretisch gehen kann. Normalisierung ist ein mächtiges Werkzeug. Sie eliminiert Redundanzen, sie sorgt für Datenintegrität, sie macht Updates und Löschungen sicher. Das sind alles gute Dinge. Aber wie bei jedem Werkzeug gibt es einen Punkt, an dem man es übertreibt. Einen Punkt, an dem die Nachteile die Vorteile überwiegen.
Unsere siebzig-Tabellen-Kontaktdatenbank ist so ein Punkt. Sie ist theoretisch perfekt. Sie hat keine Redundanzen. Jede Information ist genau einmal gespeichert. Änderungen an Lookup-Daten wirken sich automatisch überall aus. Historisierung ist eingebaut. Alles ist sauber, strukturiert, elegant.
Aber sie ist auch ein Performance-Albtraum. Um einen einzelnen Kontakt mit allen Details anzuzeigen, müsste man zwanzig, dreißig Tabellen joinen. Jede Abfrage würde ewig dauern. Indizes könnten nur bedingt helfen, weil die Datenbank einfach zu fragmentiert ist. Das Caching würde zum Problem, weil jede kleine Änderung potentiell Dutzende von Caches invalidiert.
Und dann ist da die Wartbarkeit. Stellt euch vor, ihr müsst in diese Struktur eine neue Telefonnummer eintragen. Ihr müsst die Telefonnummer-Tabelle befüllen, die Ländervorwahl nachschlagen, den Telefontyp auswählen, die Verknüpfungstabelle befüllen, das Hauptnummer-Flag setzen. Das sind mindestens fünf verschiedene Operationen, die alle in einer Transaktion laufen müssen. Ein Fehler, und alles ist inkonsistent.
Und die Komplexität für den Entwickler! Jeder neue Entwickler, der in dieses Projekt kommt, würde eine Woche brauchen, nur um die Struktur zu verstehen. Dokumentation? Ja, die wäre nötig. Sehr viel Dokumentation. Und selbst dann würde man ständig nachschauen müssen, welche Tabelle jetzt für was zuständig ist.
Zweitens: Weil es Spaß macht. Ernsthaft. Es macht Spaß, mal theoretisch bis zum Äußersten zu gehen. Es macht Spaß, ein Gedankenexperiment durchzuziehen und zu sehen, wo es hinführt. Und es macht Spaß, am Ende zu sagen: “Okay, das war interessant, aber in der Praxis machen wir es anders.”
Wo liegt die Balance?
Die Frage, die wir uns stellen sollten, ist nicht “Wie weit kann ich normalisieren?”, sondern “Wie weit sollte ich normalisieren?”. Und die Antwort darauf ist, wie so oft in der Softwareentwicklung: Es kommt darauf an.
Für eine Kontaktdatenbank in der Praxis würde ich wahrscheinlich mit zehn bis fünfzehn Tabellen arbeiten. Kontakte, Firmen, Adressen, Telefonnummern, E-Mails, vielleicht Websites. Dazu ein paar Lookup-Tabellen für Länder, Adresstypen, Telefontypen. Vielleicht eine Verknüpfungstabelle für die Kontakt-Firma-Beziehung, wenn das Anforderungen erfordern.
Aber ich würde nicht jede kleinste Information in eine eigene Tabelle auslagern. Ich würde Ortsvorwahlen nicht von der Telefonnummer trennen. Ich würde die Ländervorwahl direkt in der Länder-Tabelle speichern, nicht in einer separaten Tabelle. Ich würde Adresszusätze als Freitextfeld behandeln, nicht als Lookup.
Warum? Weil die Balance wichtig ist. Balance zwischen Normalisierung und Performance. Balance zwischen Datenintegrität und Wartbarkeit. Balance zwischen theoretischer Eleganz und praktischer Brauchbarkeit.
Normalisierung ist kein Selbstzweck. Sie ist ein Mittel zum Zweck. Der Zweck ist eine funktionierende, wartbare, performante Datenbank. Wenn Normalisierung diesen Zweck unterstützt, ist sie gut. Wenn sie ihm im Weg steht, muss man einen Schritt zurücktreten und denormalisieren.
FileMaker-spezifische Überlegungen
Als FileMaker-Entwickler haben wir noch ein paar zusätzliche Dinge zu bedenken. FileMaker ist kein klassisches SQL-Datenbanksystem. Es hat seine eigenen Stärken und Schwächen, seine eigenen Paradigmen.
FileMaker ist visuell. Beziehungen werden im Beziehungsgraphen dargestellt. Ein Beziehungsgraph mit siebzig Tabellen? Das ist kein Graph mehr, das ist ein Chaos. Man würde den Überblick verlieren. Man würde sich permanent verirren. Man würde neue Beziehungen übersehen oder alte falsch verknüpfen.
FileMaker ist portalbasiert. Wenn wir Daten aus verknüpften Tabellen anzeigen wollen, nutzen wir Portale. Aber Portale haben Grenzen. Man kann nicht beliebig tief graben. Jedenfalls nicht ohne verrückt zu werden. Man kann nicht beliebig viele Joins machen, ohne dass die Performance leidet. Eine übernormalisierte Struktur würde uns zwingen, Portale in Portalen zu verwenden (geht nicht), verschachtelte Selects, komplexe Berechnungen. Das würde langsam werden. Sehr langsam.
Und dann ist da noch die Frage der Wertelisten. In unserer übernormalisierten Datenbank haben wir Dutzende von Lookup-Tabellen. AdressTypen, TelefonTypen, EmailTypen, und so weiter. In FileMaker würde man viele davon einfach als Wertelisten implementieren. Wertelisten sind schnell, einfach zu warten, und für die meisten Fälle völlig ausreichend. Man braucht keine eigene Tabelle für drei Werte.
Das heißt nicht, dass Normalisierung in FileMaker unwichtig wäre. Ganz im Gegenteil. Aber es heißt, dass man die FileMaker-spezifischen Werkzeuge und Konzepte berücksichtigen muss. Man muss pragmatisch sein. Man muss die Sprache sprechen, die FileMaker versteht.
Die Lehren: Was wir mitnehmen
Was lernen wir aus diesem Wahnsinn? Was nehmen wir mit aus unserem Ausflug in die Über-Normalisierung?
Erstens: Normalisierung ist wichtig. Sie sorgt für Datenintegrität, sie eliminiert Redundanzen, sie macht unsere Datenbanken robuster. Wir sollten sie nicht ignorieren, nicht aus Bequemlichkeit, nicht aus Unwissenheit.
Zweitens: Normalisierung ist kein Dogma. Es gibt Situationen, in denen Denormalisierung die richtige Wahl ist. Wenn Performance kritisch ist, wenn die Daten sowieso nicht oft geändert werden, wenn die zusätzliche Komplexität den Nutzen übersteigt. Man muss abwägen, Fall für Fall, Tabelle für Tabelle.
Drittens: Theorie und Praxis sind zwei verschiedene Dinge. Was in einem Lehrbuch steht, was in einem Universitätskurs vermittelt wird, muss nicht zwangsläufig eins zu eins in die Praxis übertragbar sein. Man muss verstehen, warum die Theorie so ist, wie sie ist. Und dann muss man entscheiden, wie man sie anwendet.
Viertens: Es macht Spaß, mal über die Stränge zu schlagen. Es macht Spaß, Grenzen auszutesten, Extreme zu erkunden, Gedankenexperimente durchzuziehen. Solange man am Ende weiß, dass es ein Experiment war, und solange man daraus lernt.
Und fünftens: Siebzig Tabellen für eine Kontaktdatenbank sind wirklich, wirklich zu viel. Bitte, bitte macht das nicht in Produktion. Ich bin nicht verantwortlich für die Konsequenzen.
Fazit: Die Kunst des Maßhaltens
Am Ende des Tages ist Datenbankdesign eine Kunst. Es ist kein strikter Prozess, kein Algorithmus, den man einfach abarbeiten kann. Es ist eine Mischung aus Wissen, Erfahrung, Intuition und gesundem Menschenverstand.
Unsere siebzig-Tabellen-Kontaktdatenbank ist ein akademisches Meisterwerk. Sie ist theoretisch perfekt. Sie ist auch praktisch unbenutzbar. Und das ist okay. Denn sie hat uns etwas gelehrt. Sie hat uns gezeigt, wie weit man gehen kann. Und damit hat sie uns auch gezeigt, wie weit man nicht gehen sollte.
Wenn ihr das nächste Mal vor einem Datenbankdesign sitzt, denkt an diese Geschichte. Denkt an die siebzig Tabellen. Lacht ein bisschen. Und dann macht es besser. Macht es praktisch. Macht es wartbar. Macht es so, dass ihr in einem Jahr noch versteht, was ihr euch dabei gedacht habt.
Normalisiert eure Datenbanken. Aber normalisiert sie mit Maß. Findet den Sweet Spot zwischen Theorie und Praxis. Und vor allem: Habt Spaß dabei. Denn am Ende des Tages sollte Entwicklung nicht nur funktional sein, sondern auch ein bisschen Freude bereiten.
Und wenn euer Chef das nächste Mal fragt, warum die Kontaktdatenbank nur zehn Tabellen hat und nicht mehr, zeigt ihm diesen Blog-Post. Sagt ihm, dass ihr wisst, wie es theoretisch geht. Aber dass ihr euch bewusst dagegen entschieden habt. Weil ihr pragmatisch seid. Weil ihr weise seid. Weil ihr keine siebzig Tabellen wollen.
Danke fürs Lesen. Und denkt dran: Normalisierung ist gut. Aber zu viel Normalisierung ist wie zu viel Koffein. Irgendwann zittert man nur noch und fragt sich, wie man hier gelandet ist.
Über z.B. https://mermaid.live könnt Ihr diesen Code Visuell darstellen lassen.
… erDiagram %% ======================================== %% KERN: KONTAKTE & PERSONEN %% ======================================== Kontakte { int KontaktID PK int AnredeID FK int TitelID FK string Vorname string Nachname date Geburtsdatum text Notizen }
Anreden {
int AnredeID PK
string Anrede
}
Titel {
int TitelID PK
string Titel
int TitelPositionID FK
}
TitelPositionen {
int TitelPositionID PK
string Position
}
%% ========================================
%% FIRMEN
%% ========================================
Firmen {
int FirmaID PK
string Firmenname
int RechtsformID FK
int BrancheID FK
}
Rechtsformen {
int RechtsformID PK
string Rechtsform
}
Branchen {
int BrancheID PK
string Branche
}
Kontakt_Firma {
int Kontakt_FirmaID PK
int KontaktID FK
int FirmaID FK
int PositionID FK
date von_Datum
date bis_Datum
}
Positionen {
int PositionID PK
string Positionsbezeichnung
}
%% ========================================
%% ADRESSEN & ORTE
%% ========================================
Adressen {
int AdresseID PK
int StrasseID FK
string Hausnummer
string HausnummerZusatz
int AdresszusatzID FK
int PLZID FK
int AdressTypID FK
}
Strassen {
int StrasseID PK
string Strassenname
int OrtID FK
}
PLZ {
int PLZID PK
string PLZ
int OrtID FK
}
Orte {
int OrtID PK
string Ortsname
int RegionID FK
}
Regionen {
int RegionID PK
string Regionsname
int LandID FK
}
Laender {
int LandID PK
string Laendername
string ISO2
string ISO3
string Laendervorwahl
int WaehrungID FK
}
Waehrungen {
int WaehrungID PK
string Waehrung
string ISO_Code
string Symbol
}
Adresszusaetze {
int AdresszusatzID PK
string Zusatz
}
AdressTypen {
int AdressTypID PK
string Typ
}
Kontakt_Adresse {
int Kontakt_AdresseID PK
int KontaktID FK
int AdresseID FK
bool IstHauptadresse
date Gueltig_von
date Gueltig_bis
}
Firma_Adresse {
int Firma_AdresseID PK
int FirmaID FK
int AdresseID FK
bool IstHauptsitz
date Gueltig_von
date Gueltig_bis
}
%% ========================================
%% TELEFON
%% ========================================
Telefonnummern {
int TelefonID PK
int LaendervorwahlID FK
string Ortsvorwahl
string Rufnummer
string Durchwahl
int TelefonTypID FK
}
Laendervorwahlen {
int LaendervorwahlID PK
string Vorwahl
int LandID FK
}
TelefonTypen {
int TelefonTypID PK
string Typ
}
Kontakt_Telefon {
int Kontakt_TelefonID PK
int KontaktID FK
int TelefonID FK
bool IstHauptnummer
date Gueltig_von
date Gueltig_bis
}
Firma_Telefon {
int Firma_TelefonID PK
int FirmaID FK
int TelefonID FK
string Abteilung
date Gueltig_von
date Gueltig_bis
}
%% ========================================
%% E-MAIL
%% ========================================
EMail_Adressen {
int EmailID PK
string EmailAdresse
int EmailTypID FK
}
EmailTypen {
int EmailTypID PK
string Typ
}
Kontakt_Email {
int Kontakt_EmailID PK
int KontaktID FK
int EmailID FK
bool IstHauptemail
date Gueltig_von
date Gueltig_bis
}
Firma_Email {
int Firma_EmailID PK
int FirmaID FK
int EmailID FK
string Abteilung
date Gueltig_von
date Gueltig_bis
}
%% ========================================
%% WEBSITES
%% ========================================
Websites {
int WebsiteID PK
string URL
int WebsiteTypID FK
}
WebsiteTypen {
int WebsiteTypID PK
string Typ
}
Kontakt_Website {
int Kontakt_WebsiteID PK
int KontaktID FK
int WebsiteID FK
}
Firma_Website {
int Firma_WebsiteID PK
int FirmaID FK
int WebsiteID FK
}
%% ========================================
%% BANKING
%% ========================================
Bankverbindungen {
int BankverbindungID PK
string IBAN
string BIC
int BankID FK
}
Banken {
int BankID PK
string Bankname
string BLZ
int LandID FK
}
Kontakt_Bankverbindung {
int Kontakt_BankverbindungID PK
int KontaktID FK
int BankverbindungID FK
bool IstHauptkonto
}
Firma_Bankverbindung {
int Firma_BankverbindungID PK
int FirmaID FK
int BankverbindungID FK
}
%% ========================================
%% STEUERN
%% ========================================
Steuer_IDs {
int SteuerID_TableID PK
string Nummer
int SteuerTypID FK
}
SteuerTypen {
int SteuerTypID PK
string Typ
int LandID FK
}
Kontakt_SteuerID {
int Kontakt_SteuerID_ID PK
int KontaktID FK
int SteuerID_TableID FK
}
Firma_SteuerID {
int Firma_SteuerID_ID PK
int FirmaID FK
int SteuerID_TableID FK
}
%% ========================================
%% BEZIEHUNGEN
%% ========================================
Beziehungen {
int BeziehungID PK
int KontaktID_1 FK
int KontaktID_2 FK
int BeziehungsTypID FK
date seit_Datum
}
BeziehungsTypen {
int BeziehungsTypID PK
string Typ
}
%% ========================================
%% SPRACHEN
%% ========================================
Kommunikationssprachen {
int KommunikationsspracheID PK
int KontaktID FK
int FirmaID FK
int SpracheID FK
int SprachlevelID FK
}
Sprachen {
int SpracheID PK
string Sprache
string ISO_Code
}
Sprachlevel {
int SprachlevelID PK
string Level
}
%% ========================================
%% TAGS
%% ========================================
Tags {
int TagID PK
string Tagname
int TagKategorieID FK
}
TagKategorien {
int TagKategorieID PK
string Kategoriename
}
Kontakt_Tag {
int Kontakt_TagID PK
int KontaktID FK
int TagID FK
}
Firma_Tag {
int Firma_TagID PK
int FirmaID FK
int TagID FK
}
%% ========================================
%% BEZIEHUNGEN (RELATIONSHIPS)
%% ========================================
%% Kontakte
Kontakte ||--o{ Anreden : "hat"
Kontakte ||--o{ Titel : "hat"
Titel ||--o{ TitelPositionen : "hat"
%% Firmen
Firmen ||--o{ Rechtsformen : "hat"
Firmen ||--o{ Branchen : "hat"
Kontakte ||--o{ Kontakt_Firma : "arbeitet bei"
Firmen ||--o{ Kontakt_Firma : "beschäftigt"
Kontakt_Firma ||--o{ Positionen : "in Position"
%% Adressen
Adressen ||--o{ Strassen : "liegt in"
Adressen ||--o{ PLZ : "hat"
Adressen ||--o{ Adresszusaetze : "hat"
Adressen ||--o{ AdressTypen : "vom Typ"
Strassen ||--o{ Orte : "in"
PLZ ||--o{ Orte : "gehört zu"
Orte ||--o{ Regionen : "in"
Regionen ||--o{ Laender : "in"
Laender ||--o{ Waehrungen : "hat"
Kontakte ||--o{ Kontakt_Adresse : "hat"
Adressen ||--o{ Kontakt_Adresse : "zugeordnet"
Firmen ||--o{ Firma_Adresse : "hat"
Adressen ||--o{ Firma_Adresse : "zugeordnet"
%% Telefon
Telefonnummern ||--o{ Laendervorwahlen : "hat"
Telefonnummern ||--o{ TelefonTypen : "vom Typ"
Laendervorwahlen ||--o{ Laender : "gehört zu"
Kontakte ||--o{ Kontakt_Telefon : "hat"
Telefonnummern ||--o{ Kontakt_Telefon : "zugeordnet"
Firmen ||--o{ Firma_Telefon : "hat"
Telefonnummern ||--o{ Firma_Telefon : "zugeordnet"
%% E-Mail
EMail_Adressen ||--o{ EmailTypen : "vom Typ"
Kontakte ||--o{ Kontakt_Email : "hat"
EMail_Adressen ||--o{ Kontakt_Email : "zugeordnet"
Firmen ||--o{ Firma_Email : "hat"
EMail_Adressen ||--o{ Firma_Email : "zugeordnet"
%% Websites
Websites ||--o{ WebsiteTypen : "vom Typ"
Kontakte ||--o{ Kontakt_Website : "hat"
Websites ||--o{ Kontakt_Website : "zugeordnet"
Firmen ||--o{ Firma_Website : "hat"
Websites ||--o{ Firma_Website : "zugeordnet"
%% Banking
Bankverbindungen ||--o{ Banken : "bei"
Banken ||--o{ Laender : "in"
Kontakte ||--o{ Kontakt_Bankverbindung : "hat"
Bankverbindungen ||--o{ Kontakt_Bankverbindung : "zugeordnet"
Firmen ||--o{ Firma_Bankverbindung : "hat"
Bankverbindungen ||--o{ Firma_Bankverbindung : "zugeordnet"
%% Steuern
Steuer_IDs ||--o{ SteuerTypen : "vom Typ"
SteuerTypen ||--o{ Laender : "in"
Kontakte ||--o{ Kontakt_SteuerID : "hat"
Steuer_IDs ||--o{ Kontakt_SteuerID : "zugeordnet"
Firmen ||--o{ Firma_SteuerID : "hat"
Steuer_IDs ||--o{ Firma_SteuerID : "zugeordnet"
%% Beziehungen zwischen Kontakten
Kontakte ||--o{ Beziehungen : "hat Beziehung zu"
Beziehungen ||--o{ BeziehungsTypen : "vom Typ"
%% Sprachen
Kommunikationssprachen ||--o{ Sprachen : "spricht"
Kommunikationssprachen ||--o{ Sprachlevel : "auf Level"
Kontakte ||--o{ Kommunikationssprachen : "spricht"
Firmen ||--o{ Kommunikationssprachen : "verwendet"
%% Tags
Tags ||--o{ TagKategorien : "in Kategorie"
Kontakte ||--o{ Kontakt_Tag : "hat"
Tags ||--o{ Kontakt_Tag : "zugeordnet"
Firmen ||--o{ Firma_Tag : "hat"
Tags ||--o{ Firma_Tag : "zugeordnet"
…
Seamless Email Integration for FileMaker – now in English!
Seamless Email Integration for FileMaker – now in English!

Now available: FM MailBridge – the add-on for anyone who wants to integrate email into their FileMaker solutions seamlessly. No external tools. No manual workarounds. Just pure IMAP.
Whether you’re using it as a standalone on your local machine, deploying it on a server, or bundling it into your own commercial FileMaker projects – FM MailBridge makes it possible to process and manage emails directly within FileMaker. Clean, efficient, and fully customizable.
What is FM MailBridge?
FM MailBridge is a standalone PHP-based module that connects directly to IMAP mailboxes and delivers structured email data – including attachments – to FileMaker via Insert from URL. The complete message is returned as JSON, including: • Sender, subject, date • Email body (plain text or HTML) • Attachments (Base64-encoded, with filename & MIME type)
The integration is designed to work with any FileMaker solution – locally, server-side, or as part of a commercial product.
Three license models to fit your needs:
-
Single User – €49 For local use by developers or single users. Runs via local web server.
-
Server – €199 For centralized use on a FileMaker Server (via scheduled script or PSOS). No client setup required.
-
Enterprise – €699 For developers and agencies who want to integrate FM MailBridge into their own FileMaker products and resell it.
Why FM MailBridge? • Direct IMAP access – no Google API or OAuth required • Works with Gmail, Outlook, hosted mailboxes, and more • Returns structured email data as JSON (incl. attachments) • Fully customizable for any FileMaker environment • No external tools – just PHP and FileMaker
Technical Background
The solution relies on a lean PHP script that connects to an IMAP inbox, fetches and processes emails, and returns them as JSON. FileMaker then handles this data within its own table structure. The setup is solid, battle-tested with thousands of messages, and intentionally lightweight.
Product page & download: filemaker-experts.de/applicati…
E-Mails per IMAP auslesen und an FileMaker übergeben -Ohne Plugin-
In vielen FileMaker-Projekten stellt sich irgendwann die Frage: Wie integriere ich eingehende E-Mails samt Anhängen möglichst flexibel in meine Lösung? Besonders dann, wenn keine Drittanbieter-Dienste gewünscht sind und alles unter eigener Kontrolle laufen soll. In einem aktuellen Projekt habe ich genau das umgesetzt, mit einer simplen, robusten Lösung per PHP und IMAP, die hervorragend mit FileMaker zusammenspielt.

Zielsetzung
Das System soll eingehende E-Mails (z. B. aus einem Support-Postfach) auslesen, alle relevanten Felder wie Betreff, Absender, Datum, Text und Anhänge verarbeiten und die Informationen strukturiert an FileMaker übergeben. Das ganze in einem JSON-Format, das sofort weiterverarbeitet werden kann.
Technischer Aufbau
Die zentrale Komponente ist ein PHP-Skript, das per imap_open() auf das Postfach zugreift und wahlweise alle oder nur ungelesene Mails verarbeitet. Um die Performance zu schonen, wird beim ersten Abruf ein Zeitraum (z. B. 30 Tage) berücksichtigt, danach nur noch UNSEEN-Mails. Das Format der zurückgegebenen Daten ist JSON.
[
{
"uid": 542,
"subject": "Neuer Auftrag",
"from": "info@kunde.de",
"date": "2025-07-10 09:22:00",
"body": "Anbei unser Auftrag...",
"attachments": [
{
"filename": "auftrag.pdf",
"mime_type": "application/pdf",
"size": 18320,
"content": "JVBERi0xLjQKJ...(Base64)",
"disposition": "attachment",
"url": "[meine-domain.de/mailanhan...](https://meine-domain.de/mailanhang/auftrag.pdf)"
}
]
}
]
Diese Daten werden dann einfach verarbeitet. In meinem ersten test ist nur ein Anhang möglich, allerdings ist die Anpassung innerhalb von FileMaker nur mit geringem Aufwand verbunden. Um die Verarbeitung von Anhängen so einfach wie möglich zu gestalten, werden die Mail-Anhänge auf dem Server gespeichert. Per JSON wird wie ersichtlich die URL zurückgeliefert. Somit ist es im Anschluss des Skriptes innerhalb von FileMaker möglich, die Dateien in FM-Containern zu speichern.
# MailAbruf in file Mail # # Aus URL einfügen [ Auswahl ; Mit Dialog: Aus ; Ziel: $$MAIL_JSON ; "[deine](https://deine)_url_test.de/cap/imap_fetch_mails.php" ] # Variable setzen [ $anzahl ; Wert: ElementeAnzahl ( JSONListKeys ( $$MAIL_JSON ; "" ) ) ] Variable setzen [ $json ; Wert: $$MAIL_JSON ] # # Variable setzen [ $i ; Wert: 0 ] # Schleife (Anfang) [ Flush: Immer ] Verlasse Schleife wenn [ $i ≥ $anzahl ] Variable setzen [ $uid ; Wert: JSONGetElement ( $json ; "[" & $i & "].uid" ) ] Variable setzen [ $subject ; Wert: JSONGetElement ( $json ; "[" & $i & "].subject" ) ] Variable setzen [ $from ; Wert: JSONGetElement ( $json ; "[" & $i & "].from" ) ] Variable setzen [ $date ; Wert: JSONGetElement ( $json ; "[" & $i & "].date" ) ] Variable setzen [ $body ; Wert: JSONGetElement ( $json ; "[" & $i & "].body" ) ] Variable setzen [ $mime ; Wert: JSONGetElement ( $json ; "[" & $i & "].mime_type" ) ] Variable setzen [ $mime_type ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].mime_type" ) ] # # Verarbeitung der Anhänge Variable setzen [ $anzahl_anhang ; Wert: ElementeAnzahl ( JSONListKeys ( $json ; "[" & $i & "].attachments" ) ) ] Wenn [ $anzahl_anhang > 0 ] Variable setzen [ $anhang_filename ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].filename" ) ] Variable setzen [ $anhang_base64 ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].base64" ) ] Variable setzen [ $mime_type ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].mime_type" ) ] Variable setzen [ $anhang_url ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].url" ) ] Ende (wenn) # # # # # Datensatz anlegen Neuer Datensatz/Abfrage Feldwert setzen [ Mails::uid ; $uid ] Feldwert setzen [ Mails::subject ; $subject ] Feldwert setzen [ Mails::from ; $from ] Feldwert setzen [ Mails::date ; $date ] Feldwert setzen [ Mails::body ; $body ] Feldwert setzen [ Mails::anhang_filename ; $anhang_filename ] Feldwert setzen [ Mails::anhang_base64 ; $anhang_base64 ] Feldwert setzen [ Mails::anhang_mime_typ ; $mime_type ] # Datei als Anhang nach FileMaker Variable setzen [ $base64 ; Wert: Mails::anhang_base64 ] Variable setzen [ $mime ; Wert: Mails::anhang_mime_typ ] Variable setzen [ $name ; Wert: Mails::anhang_filename ] # Data URL vorbereiten Feldwert setzen [ Mails::anhang_url ; $anhang_url ] Aus URL einfügen [ Auswahl ; Mit Dialog: Aus ; Ziel: Mails::anhang_container ; Mails::anhang_url ] Variable setzen [ $i ; Wert: $i + 1 ] # Nun den Dateianhang wieder löschen Variable setzen [ $deleteURL ; Wert: "[deine](https://deine)_url_test.de/cap/delete_attachment.php?file=" &Mails::anhang_filename ] Scriptpause setzen [ Dauer (Sekunden): 1 ] Aus URL einfügen [ Auswahl ; Mit Dialog: Aus ; Ziel: $$ANTWORT ; $deleteURL ] Schleife (Ende)
Um nicht die Anhänge längerfristig auf dem Server zu speichern, wird nach einer Scriptpause, ein weiteres PHP-Script aufgerufen. Dieses löscht den Anhang und stellt somit sicher, das dieser nicht über eine URL sichtbar gemacht werden kann.

Diese Lösung ist ideal für FileMaker-Projekte, bei denen volle Kontrolle über das E-Mail-System gewünscht ist. Sie erfordert kein IMAP-Plugin, kein MBS, keine externen Dienste und ist vollständig serverbasiert. Alles steuerbar über einfache URL-Aufrufe. Der Abruf von E-Mails wird so zum automatisierten Teil des Workflows, vom Posteingang bis zur direkten Weiterverarbeitung in FileMaker.
Mein Artikel ist im FileMaker Magazin erschienen!
Nun noch das aktuelle PDF als Auszug aus dem Magazin.
Mein Artikel ist im FileMaker Magazin erschienen!
Mein Artikel ist im FileMaker Magazin erschienen!

Ich zeige darin, wie man eine sequentielle Suche mit PHP und FileMaker umsetzen kann. Eine Lösung, die auch bei großen Datenmengen performant bleibt.
Die Idee entstand, als ein bestehender Ansatz bei einem Kunden plötzlich ins Stocken geriet. Statt den Suchprozess in FileMaker zu quälen, habe ich den Fokus verlagert: -Export per CSV, -Suche in PHP, -Rückgabe der IDs per fmp://URL – und das alles ohne Plugins oder externe Datenbank.
Highlights aus dem Artikel: • FileMaker-Export als Tab-getrennte Datei • Upload via Insert from URL und cURL • serverseitige Verarbeitung mit PHP • blitzschnelle Filterung im WebViewer • Rückübergabe der gefundenen IDs an FileMaker • robust, portabel und unabhängig von der Datenstruktur
Jetzt nachzulesen im FileMaker Magazin, Ausgabe 07/2025: „Sequentielle Suche – Arbeitsteilung zwischen FileMaker und PHP“ (von Ronny Schrader | MaRo-Programmierung GbR)
Wer Interesse an der Lösung oder einer Demo-Datei hat, darf sich gern bei mir melden.
FileMaker aufgefrischt - Aus Alt wird endlich Neu
Nach vielen Jahren im Einsatz wurde es Zeit, die Kartenansicht grundlegend zu überarbeiten. Zwischen Wunsch nach mehr Übersicht und den Grenzen der alten Lösung entstand eine neue, moderne Oberfläche mit klarer Struktur und deutlich mehr Möglichkeiten.
Die ursprünglich in FileMaker integrierte Google-Maps-Anzeige im WebViewer war in die Jahre gekommen, höchste Zeit für eine grundlegende Neugestaltung. Der Kunde hatte den Wunsch geäußert, deutlich mehr Informationen direkt in der Kartenansicht sichtbar zu machen. In den letzten Monaten investierte ich daher erhebliche Zeit in die datenbasierte Aufbereitung, um trotz wachsender Informationsdichte eine möglichst klare Darstellung zu ermöglichen.
Doch schließlich war ein Punkt erreicht, an dem Aufwand und Ergebnis in keinem sinnvollen Verhältnis mehr standen. Insbesondere das Konzept individueller Google-Maps-Symbole zur Darstellung der beteiligten Mitarbeiter stieß an seine Grenzen. Sobald mehr als zwei Personen pro Auftrag abgebildet werden mussten, wäre die Anzahl benötigter Symbolvarianten explodiert. Zwar hätte dies einen hohen Informationsgehalt geboten, gleichzeitig aber eine technische Komplexität verursacht, die nicht mehr zeitgemäß erschien.
Die neue Oberfläche überzeugt durch zeitgemäßes Design und funktionale Erweiterungen. Suchen, Gruppieren und der direkte Zugriff auf auftragsspezifische Aktionen sind nun nahtlos integriert.

Die bestehende Lösung ist technisch wie gestalterisch überholt. Eine zeitgemäße Anpassung wäre nur mit großem Ressourcenaufwand möglich gewesen und damit nicht mehr wirtschaftlich.



Sequentielle Suche mit FileMaker und PHP
Manchmal sind es nicht die großen Frameworks oder hochkomplexen API-Integrationen, die den Unterschied machen, sondern ein bewusst einfacher, robuster Ansatz, der sich nahtlos in vorhandene Workflows integriert. Genau das war der Ausgangspunkt für eine kleine aber wirkungsvolle Lösung, die FileMaker mit einem PHP-basierten Webinterface verbindet – mit dem Ziel, eine sequentielle Suche über eine größere Datenmenge performant und flexibel umzusetzen.
Das derzeitige Problem beim Kunden, vor Jahren habe ich eine Sequentielle Suche nativ in FileMaker umgesetzt. Die übliche Vorgehensweise, ein Script sucht bei jedem Tastenanschlag, genutzt werden alle Felder die in der Schnellsuche eingeschlossen sind. Über die Jahre wuchs der Datenbestand, es wurden Felder innerhalb von Ausschnitten erfasst. Es musste so kommen, der Kunde konnte die Suche kaum mehr nutzen, tippen, warten, tippen. Sehr unschön und langsam.
Dann kam mir im Zuge einer Listenansicht, in die ich eine Suche integriert habe, die Idee. FileMaker überträgt per -Aus URL einfügen- Tabellendaten an ein PHP-Script. Im WebViewer wird dann die Tabelle angezeigt, nebst einem Suchfeld. Also frisch ans Werk gemacht und schnell festgestellt, die Felder in Variablen zu verpacken, macht in der Menge keinen Spaß. Also das ganze per Schleife, Feldnamen holen, die Werte dazu sammeln. In Schleife, ist das gut machbar, aber trotzdem ein nicht unerheblicher Zeitaufwand. Dann eine Eingebung, exportiere die Tabelle und verarbeite die Daten direkt auf dem Server per PHP.

Vorgehen: FileMaker exportiert eine strukturierte Datenmenge als CSV – diese Datei wird im Hintergrund automatisch an ein kleines PHP-Script übermittelt. Dort wird sie interpretiert, analysiert und in einer visuellen Oberfläche dargestellt, über die eine freie Volltextsuche möglich ist. Der Clou: Mit jedem Tastendruck wird die Ergebnisliste dynamisch reduziert – und bei Bedarf lassen sich über die Enter-Taste direkt Projektnummern an ein FileMaker-Script zurückgeben, das dann wiederum die interne Detailansicht aktualisiert. Ganz ohne Datenbankabfragen im Webserver, ganz ohne MySQL, Redis oder externe Services.
Die PHP-Logik bleibt dabei angenehm überschaubar. Ein Beispiel für das Parsen und Darstellen der Daten sieht so aus:
<?php
$csvData = [];
$data = file_get_contents("php://input");
if ($data && strlen($data) > 0) {
$lines = preg_split('/\r\n|\r|\n/', $data);
foreach ($lines as $line) {
if (trim($line) !== "") {
$csvData[] = str_getcsv($line, "\t"); // Tab-getrennt
}
}
if (!empty($csvData) && empty(array_filter(end($csvData)))) {
array_pop($csvData);
}
}
$spaltenIndizes = range(0, count($csvData[0] ?? []) - 1);
?>
In der Darstellung im WebViewer werden alle Datensätze tabellarisch angezeigt. Der Clou kommt mit JavaScript: Dort wird bei jeder Eingabe automatisch geprüft, welche Zeilen noch zum aktuellen Suchbegriff passen. Zusätzlich hebt ein kleiner Style-Block die passenden Zellen farblich hervor, um die Treffer visuell zu unterstützen. Und weil alles clientseitig passiert, bleibt es schnell – auch bei mehreren tausend Einträgen.
Besonders elegant wirkt die Integration in FileMaker: Die Projektnummern der sichtbaren Zeilen werden bei einem Enter-Klick gesammelt und per fmp://-URL an ein FileMaker-Script übergeben. Diese Direktverbindung ermöglicht, das Webinterface wie eine native Erweiterung der Datenbank zu nutzen – ohne Performanceverlust, ohne Redundanz, ohne Hürden.
document.getElementById("searchInput").addEventListener("keypress", function(event) {
if (event.key === "Enter") {
event.preventDefault();
const rows = document.querySelectorAll("#csvTable tbody tr:not(.hide)");
const ids = [];
rows.forEach(row => {
const id = row.querySelectorAll("td")[0]?.textContent.trim(); // Erste Spalte = ID
if (id) ids.push(id);
});
if (ids.length > 0) {
const param = encodeURIComponent(ids.join("|"));
const url = `fmp://$/AVAGmbH?script=Projekt_LIST_Suche_PHP¶m=${param}`;
window.location.href = url;
}
}
});
Nach dem Klick, startet das FM-Script. Wir holen uns die ID,s nach üblicher Vorgangsweise und suchen in Schleife alle ID,s zusammen. In dem Zug, wird natürlich auch das Suchfenster in FileMaker geschlossen.

Diese Form der sequentiellen Suche hat sich im Test als stabil und pflegeleicht erwiesen – gerade in Szenarien, in denen FileMaker allein bei umfangreichen Datensätzen an die Grenzen kommt, etwa bei mehrdimensionalen Suchen über unstrukturierte Felder oder bei extern generierten Listen.
Und auch wenn es kein High-End-AI-Suchcluster ist: Die Lösung hat Charme. Weil sie genau das tut, was sie soll. Weil sie den Workflow nicht verbiegt, sondern erweitert. Und weil sie etwas bietet, das man oft zu selten hat: unmittelbare Rückmeldung und Kontrolle über den gesamten Prozess.
Jetzt wird nur noch ein wenig mit CSS das ganze verschönt, dann kann der Kunde damit arbeiten.
Grundlegende Fehler bei der Nutzung von Formeln in FileMaker – und wie man sie vermeidet
Grundlegende Fehler bei der Nutzung von Formeln in FileMaker – und wie man sie vermeidet
Formeln sind in FileMaker ein mächtiges Werkzeug, das eine Vielzahl von Funktionen und Berechnungen ermöglicht. Doch die unsachgemäße Nutzung von Formeln kann schnell zu erheblichen Performance-Problemen und schwer zu wartenden Datenbanklösungen führen. Heute will ich diese Problematik einmal beleuchten.
- Ungespeicherte Berechnungen überstrapazieren
Eine ungespeicherte Berechnung wird jedes Mal neu berechnet, wenn ein Datensatz angezeigt oder referenziert wird. Das bedeutet, dass komplexe Berechnungen in großen Tabellen die Leistung massiv beeinträchtigen können.
Beispiel:
Eine Formel wie Sum(Bestellungen::Betrag) wird jedes Mal neu berechnet, wenn der Kunde angezeigt wird.
Lösung: • Verwende gespeicherte Felder, wenn die Werte sich nicht ständig ändern. • Nutze Skripte, um Berechnungsergebnisse in einem statischen Feld zu speichern, das nur bei Bedarf aktualisiert wird.
- Verschachtelte und komplexe Formeln
Lange verschachtelte Formeln können schwer zu lesen, zu warten und vor allem langsam sein. FileMaker muss jeden Teil einer komplexen Formel bei jeder Neuberechnung analysieren.
Beispiel:
If( Rechnungen::Status = “Bezahlt”; Rechnungen::Summe * 0.19; If(Rechnungen::Status = “Offen”; Rechnungen::Summe * 0.25; 0) )
Lösung: • Teile komplexe Formeln in mehrere einfache Schritte auf. • Verwende Hilfsfelder oder Skripte, um Zwischenberechnungen durchzuführen. Zumal in diesem Beispiel eine einfache Formel, im deutschen FileMaker setzeVar(), häufig die Beste Lösung ist. Gerade Anfänger scheuen sich aber diese zu verwenden weil, diese unübersichtlich erschein. Kleiner Tipp am Rande, ich habe die immer als formatierte Vorlage in meinem Textexpander. Wenn ich das -$var- eintippe, erscheint das: SetzeVar ( [ Var1 = Ausdruck1 ; Var2 = Ausdruck2… ] ; Rechenanweisung ) Einfach sofort zu erkennen was gemeint ist, so ist auch die Nutzung super übersichtlich.
- Dynamische Formeln in Listen und Tabellen
In Layouts, die viele Datensätze gleichzeitig anzeigen (z. B. Tabellenansichten), werden ungespeicherte Formeln für alle angezeigten Datensätze gleichzeitig berechnet. Dies führt zu merklichen Verzögerungen.
Beispiel:
Ein berechnetes Feld zeigt den Namen eines verbundenen Objekts, etwa Bestellungen::Kunden::Name.
Lösung: • Verwende Lookup-Felder, um Werte aus verbundenen Tabellen einmalig zu kopieren. • Zeige in der Tabellenansicht nur unbedingt notwendige Daten an.
- Fehlende Indizes
Indizes sind entscheidend für die Geschwindigkeit von Berechnungen, insbesondere bei Relationen, Suchen und Filtern. Ohne Indizes dauert das Durchsuchen großer Tabellen erheblich länger.
Beispiel:
Ein Beziehungsschlüssel wie _test(Artikel::Name) ist nicht indizierbar.
Lösung: • Verwende indizierbare Felder als Beziehungsschlüssel. • Füge Hilfsfelder hinzu, die den indizierten Wert speichern (z. B. ein zusätzliches Feld NameKlein mit der gespeicherten Formel Lower(Name)).
- Formeln statt Skripte
Oft werden Berechnungen in Formeln realisiert, obwohl Skripte besser geeignet wären. Skripte bieten die Möglichkeit, Berechnungen gezielt auszuführen und Ergebnisse zu speichern, ohne die Performance dauerhaft zu belasten.
Beispiel:
Ein Feld mit der Formel LetzteAktualisierung = Max(Änderungen::Zeitstempel) wird jedes Mal berechnet, wenn der Datensatz angezeigt wird.
Lösung: • Verwende ein Skript, das das Feld bei Änderungen aktualisiert. • Nutze Skript-Trigger, um Werte bei Benutzeraktionen zu berechnen.
- Fehlerhafte Verwendung von globalen Feldern
Globale Felder sind hilfreich, aber oft werden sie für falsche Zwecke eingesetzt, was zu Performance-Problemen führen kann.
Beispiel:
Ein globales Feld wird in einer Beziehung verwendet, um dynamische Filter zu setzen.
Lösung: • Prüfe, ob ein Skript geeigneter ist. • Verwende globale Felder nur für Werte, die sich selten ändern oder systemweit benötigt werden. Häufig nutzte ich diese nur um einen Filter zu setzen. Im allgemeinen machen diese Felder wenig Sinn.
- Übermäßige Nutzung von Aggregatfunktionen
Funktionen wie Sum, Count oder List sind praktisch, können aber bei großen Datenmengen problematisch sein, insbesondere wenn sie über mehrere Relationen hinweg berechnen.
Beispiel:
Sum(Bestellungen::Gesamtbetrag)
Wird für jeden Kunden bei jedem Zugriff neu berechnet.
Lösung: • Nutze Zwischenspeicher, z. B. ein Feld, das bei Änderungen in Bestellungen per Skript aktualisiert wird. • Verwende Statistiktabellen oder Berichte, um Aggregatwerte gezielt zu berechnen. (Aber auch hier ist Vorsicht angebracht, nutze lieber ein PHP Script, baue die Anzeige über ein HTML im WebViewer)
- Übersehen von Feldtypen
Manchmal werden Berechnungen fehlerhaft und dadurch zur echten Bremse, weil der Feldtyp nicht passt – etwa bei der Verarbeitung von Text als Zahl oder umgekehrt.
Lösung: • Stelle sicher, dass die Feldtypen korrekt definiert sind (z. B. Zahlenfelder für numerische Berechnungen).
-
Layoutformel als neues Futures Layoutformeln sind eine echte Erleichterung. Mal schnell einen Wert in einem Layout darstellen, kein Feld, kein Script, keine globale Variable. Aber mit jeder Erleichterung für den Entwickler erkauft man sich ein negativen Punkt. In unserem Fall die Performance.
-
Bedingte Formatierungen in Listenansichten. Ja, wer bis hier gelesen hat, kann sich den Rest denken. Die Liste mit 20000 Datensätzen öffnet sich und FileMaker rechnet jetzt erstmal brav die Bedingungen durch um z.B. einen Farbton eines Symbols zu ändern. Bei kleinen Datenmengen überhaupt kein Problem, aber bei vielen Werten sollte es anders gemacht werden. Wie gehts auch anders? Eine extra Tabelle für Symbole, diese wird je nach Status über eine mit dem Status in Verbindung stehende Referenz verknüpft. Dann halte ich z.B. das Symbol einmal als grünes Symbol vor, einmal als gelbes, einmal als rotes Symbol. Das lässt sich natürlich gewaltig aufblähen, macht viel Arbeit, aber es bringt echten Performance-Schub.
Fazit: Verwende wenig bis keine Formeln Es ist einfach wichtig wenige Formeln zu verwenden. Klar ist der Aufwand für jede Berechnung ein Script zu starten enorm, aber es bringt den Unterschied. Ich habe gerade letztens für ein Unternehmen arbeiten dürfen. Die Datenbank, eine Datenbank mit 20 Jähriger Historie. Die Anforderung des Auftraggebers, Performance-Probleme zu beheben. Aber der Erste Blick in die Tabellen zeigte das ganze Ausmass, 2/3 der Tabellen bestanden aus Formeln. Was will ich da noch retten? Eigentlich ein Fall für die Tonne. Abhilfe konnten teilweise Auslagerungen in Server-Scripts bringen, aber das grundsätzliche Problem konnte nicht behoben werden.
Was sind deine Erfahrungen mit Formeln in FileMaker? Teile deine Gedanken und Tipps in den Kommentaren!
Kreditkartenabrechnung mit FileMaker Teil 2
Nachdem wir im ersten Teil die Grundvoraussetzungen erarbeitet haben gehen wir nun zum eigentlichen Teil innerhalb von FileMaker über.
Für die Anzeige der Daten vom Zahlungs-Dienstleister nutzen wir ein kleines Feld vom Typ WebViewer. Die URL des WebViewers ergibt sich aus dem Pfad zum PHP-Script auf dem Webserver und unseren Parametern die wir aus FileMaker auslesen:
URL.Parameter= “http://www……………………com/Semicon2012/request.php”
&
“?"&“LastName=” & KONTAKT.T_Last_Name & “&” &“Price="&Preis_Heidel_Uebertragung&"&” & “Street=” & KONTAKT.T_Adress & “&” & “Zip=” & KONTAKT.Z_ZIP & “&” & “Stadt=” & KONTAKT.T_City & “&” & “Land=” & KONTAKT.T_Country & “&” & “Mail=” & KONTAKT.T_EMail & “&” & “Buchung=” & INVOICE.BUCHUNG.Nr_1_2 & “&” & “FirstName=” & KONTAKT.T_First_Name&"&” & “Code=” & KONTAKT.SICHERHEIT.CODE
Als Webadresse vergeben wir das Feld URL.Parameter
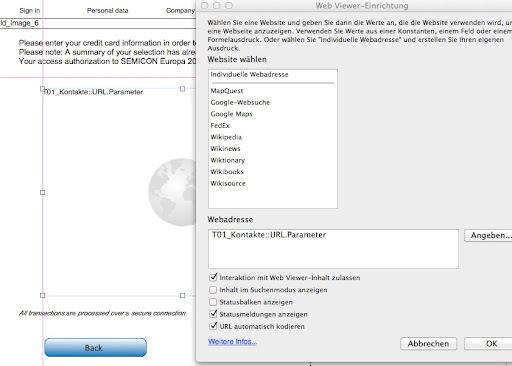
Rufen wir nun das Layout auf und der WebViewer wird aktiv erscheint die Eingabemaske vom Zahlungs-Dienstleister incl. der eingegeben Parameter wie Zahlungsbetrag, Adresse und anderer Werte.
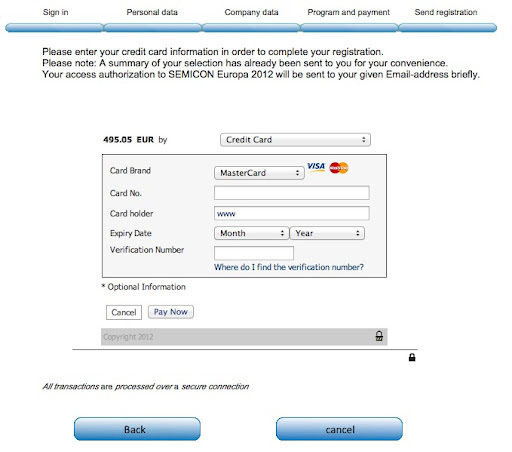
Nun gibt der Kreditkarteninhaber nur noch seine Kartennummer ein und die Verifikation Number. Nach dem Klick auf Pay Now wird vom Zahlungs-Dienstleister die Zahlung verarbeitet. Im Anschluss wird das PHP-Script “www……………………com/Semicon2012/response.php” aufgerufen.
Das Script ruft je nach Wunsch eine URL auf die dann wieder in unserem WebViewer angezeigt wird.
<?php
//this page is called after the customer finishes
//payment with the Web Payment Frontend.
//It must be hosted YOUR system and accessible
//to the outside world.
//It always must respond with a URL that defines
//which page the WPF should redirect to.
//this new page also MUST be hosted on your system
//AND it musst be accessible so that the WPF can
//redirect the users browser to it.
// PROCESSING.RESULT gets PROCESSING_RESULT when posting back (URL encoding)
$returnvalue=$_POST[‘PROCESSING_RESULT’];
if ($returnvalue)
{
if (strstr($returnvalue,“ACK”))
{
print “Location: http://www…………………………com/Semicon2012/success.html”;
}
else
{
print “http://www……………………………com/Semicon2012/error.html”;
}
}
?>
Wird als Wert ACK vom Zahlungs-Dienstleister an das Script zurückgegeben wird die URL für die erfolge Transaktion aufgerufen. ACK ist immer der Wert für erfolgte Transaktionen.
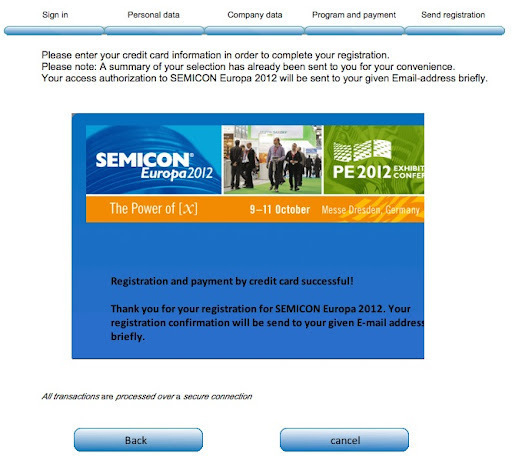
Nun da wir wissen welcher Wert im WebViewer auftaucht, müssen wir diesen nur noch überprüfen.
Über GetLayoutObjectAttribute(“Webviewer” ; “Source”) können wir den Inhalt des WebViewers abfragen. Vergleichen wir diesen ausgelesenen Inhalt z.B. mit der Funktion Exakt (InhaltWebViewer; Vergleichsfeld) können wir bestimmen ob eine Transaktion erfolgt ist oder nicht.
Mit dieser Methode kann man Kreditkartenlösungen ohne Plugin realisieren.
Dynamische Menüsteuerung Teil 2
Die Tabellen haben wir vorbereitet und arbeiten am Layout weiter. Wir benötigen in unserem Fall innerhalb eines Wunschlayouts ein -Portal- der Tabelle -T18i_timesheet_MENUE||id_constant|

Die Tabelle -T18i_timesheet_MENUE||id_constant| ist eine Instanz der Tabelle MEN_Menue. Dieses ist in meinem Fall die Tabelle des Hauptmenüs. Im Portal finden sich nun die Felder -Menue_Name-, -Menue_Icon-,-Menue_Icon_Rand- und Menue_Icon.

Nach verlassen des Layout-Modus erschein der Button aus dem Feld -Menue_Icon_Rand-, das Symbol aus dem Feld -Menue_Icon- und die Bezeichnung aus dem Feld -Menue_Name-. Das Dynamische Menü ist somit fast fertig. Was fehlt uns? Ein Script zum erkennen der Mausklicks.
Im nächsten und letzten Teil gehe ich auf die Script-Steuerung ein.
Dynamische Menüsteuerung Teil 1