Datenbanken
Der 70-Tabellen Wahnsinn: Eine Kontaktdatenbank im Normalisierungs-Rausch
Oder: Wie man aus einer simplen Adressverwaltung ein akademisches Meisterwerk der Über-Architektur erschafft*

Ein gefährliches Gedankenspiel
Heute Morgen saß ich am Schreibtisch, starrte auf meine FileMaker-Lösung und dachte mir: “Wäre es nicht herrlich, einmal komplett durchzudrehen?” Nicht im Sinne von schlechtem Code oder wilden Skripten, sondern im Sinne von theoretischer Perfektion. Von akademischer Reinheit. Von Normalisierung, die so weit geht, dass selbst Edgar F. Codd sich im Grab umdreht und fragt: “Habe ich das wirklich so gemeint?”
Heute nehme ich euch mit auf eine Reise in die dunkle Seite der Datenbankentwicklung. Wir werden gemeinsam eine Kontaktdatenbank bauen, die so übernormalisiert ist, dass sie in der Praxis völlig unbrauchbar wäre. Wir sprechen von siebzig Tabellen. Siebzig! Für Kontakte, Adressen und ein bisschen Drumherum. Das ist ungefähr so, als würde man einen Nagel mit einem Vorschlaghammer einschlagen, während man auf einem Einrad balanciert und dabei Schach spielt.
Vorweg: Das solltet ihr niemals tun. Aber es macht wahnsinnig viel Spaß, und man lernt dabei eine Menge über Normalisierung, Beziehungen und darüber, wann genug wirklich genug ist.
Die Ausgangslage: Eine ganz normale Kontaktdatenbank
Stellen wir uns vor, wir wollen eine Kontaktdatenbank bauen. Nichts Wildes. Einfach Namen, Adressen, Telefonnummern, E-Mails. Das Zeug, das jeder braucht. In der Praxis würde man vielleicht mit drei, vier Tabellen davonkommen. Kontakte, Adressen, Telefonnummern, E-Mails. Fertig. Schön übersichtlich, performant, wartbar.
Aber wo bleibt da der Spaß? Wo ist die theoretische Eleganz? Wo sind die Normalformen, von denen alle reden, die aber keiner wirklich konsequent durchzieht? Genau hier fängt unser Abenteuer an.
Der Plan: Maximale Normalisierung
Die Idee ist simpel: Wir normalisieren alles, was nicht bei drei auf den Bäumen ist. Jede noch so kleine Information bekommt ihre eigene Tabelle. Jede Redundanz wird gejagt und eliminiert. Jede transitive Abhängigkeit wird aufgelöst. Wir gehen nicht nur bis zur dritten Normalform, nicht mal bis zur BCNF. Wir gehen bis zur fünften, vielleicht sogar sechsten Normalform, wenn wir wirklich übermütig werden.
Das Ergebnis? Eine Datenbank-Struktur, die aussieht wie ein Spinnennetz nach einem Tornado. Oder wie der Stammbaum der britischen Königsfamilie. Oder wie mein Schreibtisch nach einer langen Entwicklungssession.
Die Kontakte: Wo alles beginnt
Fangen wir harmlos an. Ein Kontakt hat einen Vornamen, einen Nachnamen, vielleicht ein Geburtsdatum. In einer normalen Welt würden wir das in eine Tabelle schreiben und fertig. Aber wir sind ja nicht normal.
Ein Kontakt hat eine Anrede. Herr, Frau, Divers. Das kann sich ändern. Das muss zentral verwaltet werden. Also brauchen wir eine Anreden-Tabelle. Klingt noch vernünftig, oder? Gut, dann machen wir weiter.
Ein Kontakt kann einen Titel haben. Dr., Prof., Dipl.-Ing. und all die schönen Dinge, mit denen Menschen sich schmücken. Aber hier wird es spannend: Manche Titel stehen vor dem Namen, manche danach. In Deutschland sagt man “Dr. Müller”, in Österreich manchmal “Müller, Dr.”. Das ist eine Information! Eine strukturierte Information! Also brauchen wir nicht nur eine Titel-Tabelle, sondern auch eine TitelPositionen-Tabelle. Zwei Tabellen, nur damit wir wissen, ob der Doktortitel vor oder nach dem Namen kommt. Herrlich übertrieben, oder?
Die Firmen: Ein Exkurs in die Unternehmensarchitektur
Kontakte arbeiten in Firmen. Das ist nichts Neues. Aber eine Firma ist nicht einfach nur ein Name. Eine Firma hat eine Rechtsform. GmbH, AG, e.K., OHG, KG, und was weiß ich noch alles. Die Rechtsform sagt etwas über die Struktur aus, über Haftung, über steuerliche Behandlung. Das ist wichtig! Also brauchen wir eine Rechtsformen-Tabelle.
Und dann ist da noch die Branche. IT, Maschinenbau, Einzelhandel, Gastronomie. Branchen ändern sich, Branchen haben Hierarchien, Branchen sind komplex. Also brauchen wir eine Branchen-Tabelle. Vielleicht sogar mit Hierarchien, aber das würde jetzt zu weit führen. Wir haben ja erst bei Tabelle Nummer acht oder so.
Und weil ein Kontakt bei mehreren Firmen arbeiten kann, gleichzeitig oder nacheinander, brauchen wir natürlich eine Verknüpfungstabelle. Kontakt_Firma. Mit Position (Geschäftsführer, Angestellter, Freelancer), mit von-Datum und bis-Datum für die Historisierung. Und die Position? Rate mal. Eigene Tabelle. Positionen-Tabelle. Weil sich Positionsbezeichnungen ändern können und wir sie zentral verwalten wollen.
Die Adressen: Ein geografisches Meisterwerk
Jetzt wird es richtig lustig. Adressen sind kompliziert. Wirklich kompliziert. Eine Adresse besteht aus einer Straße, einer Hausnummer, einer Postleitzahl, einem Ort, einem Land. Das würde die meisten zufriedenstellen. Aber nicht uns. Oh nein.
Fangen wir mit der Straße an. Eine Straße hat einen Namen. Aber eine Straße gehört zu einem Ort. Und verschiedene Orte können Straßen mit dem gleichen Namen haben. Die Hauptstraße in Berlin ist nicht die Hauptstraße in München. Also brauchen wir eine Strassen-Tabelle, die zu einem Ort gehört. Schon haben wir eine Redundanz eliminiert.
Die Postleitzahl? Die gehört zur Adresse, nicht zum Ort! Ein großer Ort kann mehrere Postleitzahlen haben. Berlin hat hunderte davon. Also brauchen wir eine PLZ-Tabelle, die wiederum zu einem Ort gehört. Moment, aber eine PLZ kann sich auch über mehrere Orte erstrecken? Stimmt! Also machen wir eine n:m-Beziehung daraus. Ups, schon wieder komplizierter.
Orte gehören zu Regionen. Bundesländer, Kantone, Staaten, je nachdem wo wir sind. Also Regionen-Tabelle. Und Regionen gehören zu Ländern. Also Länder-Tabelle. Und Länder haben ISO-Codes, zweibuchstabig und dreibuchstabig, und Ländervorwahlen für Telefonnummern. Und eine Währung! Also brauchen wir auch noch eine Währungen-Tabelle.
Ach, und ich habe fast die Adresszusätze vergessen. “c/o”, “bei”, “℅”. Das sind strukturierte Informationen! Adresszusätze-Tabelle. Und natürlich brauchen wir eine AdressTypen-Tabelle, denn eine Adresse kann privat, geschäftlich, eine Lieferadresse oder eine Rechnungsadresse sein.
Und weil sowohl Kontakte als auch Firmen mehrere Adressen haben können, brauchen wir Verknüpfungstabellen. Kontakt_Adresse und Firma_Adresse. Mit einem Flag, welche die Hauptadresse ist. Und mit Gültigkeitsdaten, denn Menschen und Firmen ziehen um.
Wir sind jetzt bei ungefähr zwanzig Tabellen. Nur für Kontakte, Firmen und Adressen. Und wir haben noch nicht einmal über Telefonnummern gesprochen.
Die Telefonnummern: Eine Ode an die Verkomplizierung
Telefonnummern sind toll. Man könnte sie einfach als String speichern und gut ist. Aber wo bleibt da die Struktur? Wo ist die Eleganz?
Eine Telefonnummer besteht aus einer Ländervorwahl, einer Ortsvorwahl, einer Rufnummer und vielleicht einer Durchwahl. Das sind vier Felder! Vier strukturierte Informationen! Also brauchen wir eine Telefonnummern-Tabelle mit all diesen Feldern.
Aber die Ländervorwahl? Die gehört zu einem Land! Also brauchen wir eine Ländervorwahlen-Tabelle, die zur Länder-Tabelle verlinkt. Ja, wir haben die Ländervorwahl schon in der Länder-Tabelle gespeichert, aber das wäre ja eine Redundanz! Also machen wir eine eigene Tabelle daraus, damit wir sauber bleiben.
Und dann ist da noch der Typ. Mobil, Festnetz, Fax, VoIP. Das sind strukturierte Kategorien. TelefonTypen-Tabelle. Natürlich.
Und weil wieder sowohl Kontakte als auch Firmen Telefonnummern haben können, brauchen wir Verknüpfungstabellen. Kontakt_Telefon und Firma_Telefon. Mit einem Flag für die Hauptnummer. Mit Gültigkeitsdaten. Ihr kennt das Spiel.
E-Mails, Websites und der Rest: Wir sind noch nicht fertig
E-Mail-Adressen? Eigene Tabelle. Mit einem EmailTyp (privat, geschäftlich, Newsletter). EmailTypen-Tabelle. Und wieder Verknüpfungstabellen für Kontakte und Firmen. Kontakt_Email, Firma_Email.
Websites? Eigene Tabelle. Mit einem WebsiteTyp (Hauptwebsite, Blog, LinkedIn, XING, Facebook, Instagram, TikTok, was auch immer). WebsiteTypen-Tabelle. Und wieder Verknüpfungstabellen. Ihr ahnt es schon.
Bankverbindungen? IBAN, BIC, und eine Referenz zur Bank. Und die Bank? Eigene Tabelle natürlich! Mit Bankname, BLZ und einer Referenz zum Land. Und wieder Verknüpfungstabellen für Kontakte und Firmen.
Steuer-IDs? Eigene Tabelle! Mit einem SteuerTyp (USt-ID, Steuernummer, UID, je nach Land). SteuerTypen-Tabelle. Die wiederum eine Referenz zum Land hat, weil verschiedene Länder verschiedene Steuertypen haben. Und wieder Verknüpfungstabellen.
Wir sind jetzt irgendwo bei vierzig, fünfzig Tabellen. Und ich habe noch ein paar Ideen.
Die Kür: Beziehungen, Sprachen und Tags
Kontakte haben Beziehungen zueinander. Ehepartner, Kinder, Geschwister, Geschäftspartner, Freunde. Das ist eine klassische n:m-Beziehung. Also brauchen wir eine Beziehungen-Tabelle, die zwei Kontakte miteinander verbindet. Und natürlich einen BeziehungsTyp. BeziehungsTypen-Tabelle. Mit einem Datum, seit wann die Beziehung besteht. Man will ja dokumentieren, wann man geheiratet hat oder wann die Geschäftsbeziehung begann.
Kontakte sprechen Sprachen. Und Firmen kommunizieren in Sprachen. Also brauchen wir eine Kommunikationssprachen-Tabelle, die entweder zu einem Kontakt oder zu einer Firma gehört. Und diese Tabelle verweist auf eine Sprachen-Tabelle mit dem Sprachennamen und ISO-Code. Und auf eine Sprachlevel-Tabelle (Muttersprache, Fließend, Grundkenntnisse), weil das Level der Sprachkenntnisse relevant ist.
Und dann sind da noch Tags. Kategorien. Labels. Wie auch immer man sie nennen will. Kontakte und Firmen können mit Tags versehen werden, um sie zu gruppieren, zu filtern, zu organisieren. Also brauchen wir eine Tags-Tabelle. Und weil Tags selbst wieder Kategorien haben können (Marketing-Tags, Projekt-Tags, Status-Tags), brauchen wir eine TagKategorien-Tabelle. Und natürlich Verknüpfungstabellen. Kontakt_Tag und Firma_Tag.
Jetzt sind wir bei siebzig Tabellen. Siebzig! Für eine Kontaktdatenbank!
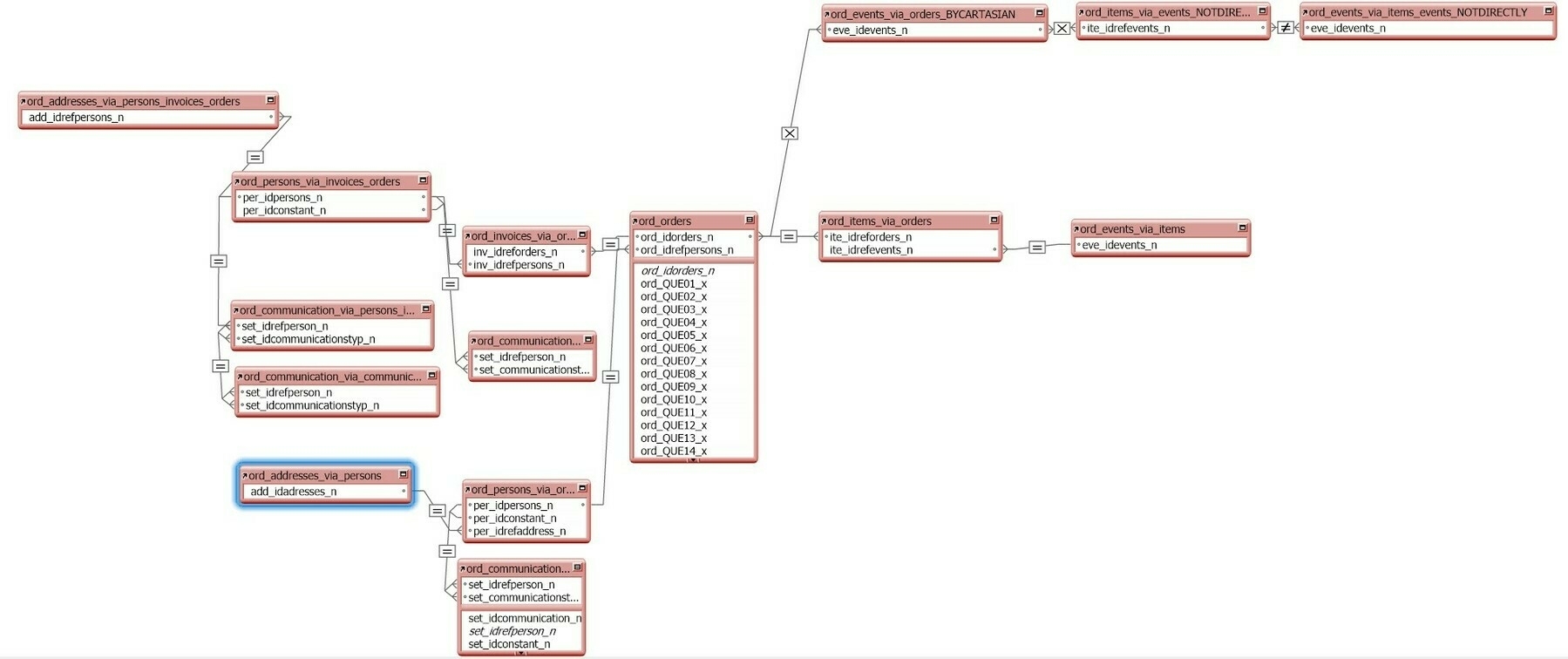
Das Diagramm: Visuelle Überforderung garantiert
An dieser Stelle sollte ich eigentlich ein Diagramm zeigen, das all diese Tabellen und ihre Beziehungen visualisiert. Aber ehrlich gesagt, das würde diesen Blog-Post sprengen. Ich habe das Diagramm erstellt. Es ist ein Monster. Es sieht aus wie ein Spinnennetz auf Steroiden. Es hat mehr Linien als ein U-Bahn-Plan von Tokio. Es ist wunderschön und schrecklich zugleich.
Wenn ihr das Diagramm sehen wollt, könnt ihr es euch als Mermaid-Datei herunterladen und in einem Tool eurer Wahl anschauen. Ich empfehle mermaid.live, denn dann könnt ihr ordentlich hinein- und herauszoomen. Ihr werdet es brauchen. Glaubt mir.
Das Diagramm zeigt jede einzelne Tabelle mit ihren Attributen, ihren Primary Keys, ihren Foreign Keys. Es zeigt jede Beziehung, jede Kardinalität, jeden Join. Es ist ein akademisches Meisterwerk. Und es ist in der Praxis völlig wahnsinnig.
Die Realität: Warum niemand das tun sollte
Jetzt fragt ihr euch wahrscheinlich: “Warum zum Teufel erzählst du uns das alles, wenn es doch sowieso niemand machen sollte?” Gute Frage. Die Antwort ist zweiteilig.
Erstens: Weil es wichtig ist zu verstehen, wie weit Normalisierung theoretisch gehen kann. Normalisierung ist ein mächtiges Werkzeug. Sie eliminiert Redundanzen, sie sorgt für Datenintegrität, sie macht Updates und Löschungen sicher. Das sind alles gute Dinge. Aber wie bei jedem Werkzeug gibt es einen Punkt, an dem man es übertreibt. Einen Punkt, an dem die Nachteile die Vorteile überwiegen.
Unsere siebzig-Tabellen-Kontaktdatenbank ist so ein Punkt. Sie ist theoretisch perfekt. Sie hat keine Redundanzen. Jede Information ist genau einmal gespeichert. Änderungen an Lookup-Daten wirken sich automatisch überall aus. Historisierung ist eingebaut. Alles ist sauber, strukturiert, elegant.
Aber sie ist auch ein Performance-Albtraum. Um einen einzelnen Kontakt mit allen Details anzuzeigen, müsste man zwanzig, dreißig Tabellen joinen. Jede Abfrage würde ewig dauern. Indizes könnten nur bedingt helfen, weil die Datenbank einfach zu fragmentiert ist. Das Caching würde zum Problem, weil jede kleine Änderung potentiell Dutzende von Caches invalidiert.
Und dann ist da die Wartbarkeit. Stellt euch vor, ihr müsst in diese Struktur eine neue Telefonnummer eintragen. Ihr müsst die Telefonnummer-Tabelle befüllen, die Ländervorwahl nachschlagen, den Telefontyp auswählen, die Verknüpfungstabelle befüllen, das Hauptnummer-Flag setzen. Das sind mindestens fünf verschiedene Operationen, die alle in einer Transaktion laufen müssen. Ein Fehler, und alles ist inkonsistent.
Und die Komplexität für den Entwickler! Jeder neue Entwickler, der in dieses Projekt kommt, würde eine Woche brauchen, nur um die Struktur zu verstehen. Dokumentation? Ja, die wäre nötig. Sehr viel Dokumentation. Und selbst dann würde man ständig nachschauen müssen, welche Tabelle jetzt für was zuständig ist.
Zweitens: Weil es Spaß macht. Ernsthaft. Es macht Spaß, mal theoretisch bis zum Äußersten zu gehen. Es macht Spaß, ein Gedankenexperiment durchzuziehen und zu sehen, wo es hinführt. Und es macht Spaß, am Ende zu sagen: “Okay, das war interessant, aber in der Praxis machen wir es anders.”
Wo liegt die Balance?
Die Frage, die wir uns stellen sollten, ist nicht “Wie weit kann ich normalisieren?”, sondern “Wie weit sollte ich normalisieren?”. Und die Antwort darauf ist, wie so oft in der Softwareentwicklung: Es kommt darauf an.
Für eine Kontaktdatenbank in der Praxis würde ich wahrscheinlich mit zehn bis fünfzehn Tabellen arbeiten. Kontakte, Firmen, Adressen, Telefonnummern, E-Mails, vielleicht Websites. Dazu ein paar Lookup-Tabellen für Länder, Adresstypen, Telefontypen. Vielleicht eine Verknüpfungstabelle für die Kontakt-Firma-Beziehung, wenn das Anforderungen erfordern.
Aber ich würde nicht jede kleinste Information in eine eigene Tabelle auslagern. Ich würde Ortsvorwahlen nicht von der Telefonnummer trennen. Ich würde die Ländervorwahl direkt in der Länder-Tabelle speichern, nicht in einer separaten Tabelle. Ich würde Adresszusätze als Freitextfeld behandeln, nicht als Lookup.
Warum? Weil die Balance wichtig ist. Balance zwischen Normalisierung und Performance. Balance zwischen Datenintegrität und Wartbarkeit. Balance zwischen theoretischer Eleganz und praktischer Brauchbarkeit.
Normalisierung ist kein Selbstzweck. Sie ist ein Mittel zum Zweck. Der Zweck ist eine funktionierende, wartbare, performante Datenbank. Wenn Normalisierung diesen Zweck unterstützt, ist sie gut. Wenn sie ihm im Weg steht, muss man einen Schritt zurücktreten und denormalisieren.
FileMaker-spezifische Überlegungen
Als FileMaker-Entwickler haben wir noch ein paar zusätzliche Dinge zu bedenken. FileMaker ist kein klassisches SQL-Datenbanksystem. Es hat seine eigenen Stärken und Schwächen, seine eigenen Paradigmen.
FileMaker ist visuell. Beziehungen werden im Beziehungsgraphen dargestellt. Ein Beziehungsgraph mit siebzig Tabellen? Das ist kein Graph mehr, das ist ein Chaos. Man würde den Überblick verlieren. Man würde sich permanent verirren. Man würde neue Beziehungen übersehen oder alte falsch verknüpfen.
FileMaker ist portalbasiert. Wenn wir Daten aus verknüpften Tabellen anzeigen wollen, nutzen wir Portale. Aber Portale haben Grenzen. Man kann nicht beliebig tief graben. Jedenfalls nicht ohne verrückt zu werden. Man kann nicht beliebig viele Joins machen, ohne dass die Performance leidet. Eine übernormalisierte Struktur würde uns zwingen, Portale in Portalen zu verwenden (geht nicht), verschachtelte Selects, komplexe Berechnungen. Das würde langsam werden. Sehr langsam.
Und dann ist da noch die Frage der Wertelisten. In unserer übernormalisierten Datenbank haben wir Dutzende von Lookup-Tabellen. AdressTypen, TelefonTypen, EmailTypen, und so weiter. In FileMaker würde man viele davon einfach als Wertelisten implementieren. Wertelisten sind schnell, einfach zu warten, und für die meisten Fälle völlig ausreichend. Man braucht keine eigene Tabelle für drei Werte.
Das heißt nicht, dass Normalisierung in FileMaker unwichtig wäre. Ganz im Gegenteil. Aber es heißt, dass man die FileMaker-spezifischen Werkzeuge und Konzepte berücksichtigen muss. Man muss pragmatisch sein. Man muss die Sprache sprechen, die FileMaker versteht.
Die Lehren: Was wir mitnehmen
Was lernen wir aus diesem Wahnsinn? Was nehmen wir mit aus unserem Ausflug in die Über-Normalisierung?
Erstens: Normalisierung ist wichtig. Sie sorgt für Datenintegrität, sie eliminiert Redundanzen, sie macht unsere Datenbanken robuster. Wir sollten sie nicht ignorieren, nicht aus Bequemlichkeit, nicht aus Unwissenheit.
Zweitens: Normalisierung ist kein Dogma. Es gibt Situationen, in denen Denormalisierung die richtige Wahl ist. Wenn Performance kritisch ist, wenn die Daten sowieso nicht oft geändert werden, wenn die zusätzliche Komplexität den Nutzen übersteigt. Man muss abwägen, Fall für Fall, Tabelle für Tabelle.
Drittens: Theorie und Praxis sind zwei verschiedene Dinge. Was in einem Lehrbuch steht, was in einem Universitätskurs vermittelt wird, muss nicht zwangsläufig eins zu eins in die Praxis übertragbar sein. Man muss verstehen, warum die Theorie so ist, wie sie ist. Und dann muss man entscheiden, wie man sie anwendet.
Viertens: Es macht Spaß, mal über die Stränge zu schlagen. Es macht Spaß, Grenzen auszutesten, Extreme zu erkunden, Gedankenexperimente durchzuziehen. Solange man am Ende weiß, dass es ein Experiment war, und solange man daraus lernt.
Und fünftens: Siebzig Tabellen für eine Kontaktdatenbank sind wirklich, wirklich zu viel. Bitte, bitte macht das nicht in Produktion. Ich bin nicht verantwortlich für die Konsequenzen.
Fazit: Die Kunst des Maßhaltens
Am Ende des Tages ist Datenbankdesign eine Kunst. Es ist kein strikter Prozess, kein Algorithmus, den man einfach abarbeiten kann. Es ist eine Mischung aus Wissen, Erfahrung, Intuition und gesundem Menschenverstand.
Unsere siebzig-Tabellen-Kontaktdatenbank ist ein akademisches Meisterwerk. Sie ist theoretisch perfekt. Sie ist auch praktisch unbenutzbar. Und das ist okay. Denn sie hat uns etwas gelehrt. Sie hat uns gezeigt, wie weit man gehen kann. Und damit hat sie uns auch gezeigt, wie weit man nicht gehen sollte.
Wenn ihr das nächste Mal vor einem Datenbankdesign sitzt, denkt an diese Geschichte. Denkt an die siebzig Tabellen. Lacht ein bisschen. Und dann macht es besser. Macht es praktisch. Macht es wartbar. Macht es so, dass ihr in einem Jahr noch versteht, was ihr euch dabei gedacht habt.
Normalisiert eure Datenbanken. Aber normalisiert sie mit Maß. Findet den Sweet Spot zwischen Theorie und Praxis. Und vor allem: Habt Spaß dabei. Denn am Ende des Tages sollte Entwicklung nicht nur funktional sein, sondern auch ein bisschen Freude bereiten.
Und wenn euer Chef das nächste Mal fragt, warum die Kontaktdatenbank nur zehn Tabellen hat und nicht mehr, zeigt ihm diesen Blog-Post. Sagt ihm, dass ihr wisst, wie es theoretisch geht. Aber dass ihr euch bewusst dagegen entschieden habt. Weil ihr pragmatisch seid. Weil ihr weise seid. Weil ihr keine siebzig Tabellen wollen.
Danke fürs Lesen. Und denkt dran: Normalisierung ist gut. Aber zu viel Normalisierung ist wie zu viel Koffein. Irgendwann zittert man nur noch und fragt sich, wie man hier gelandet ist.
Über z.B. https://mermaid.live könnt Ihr diesen Code Visuell darstellen lassen.
… erDiagram %% ======================================== %% KERN: KONTAKTE & PERSONEN %% ======================================== Kontakte { int KontaktID PK int AnredeID FK int TitelID FK string Vorname string Nachname date Geburtsdatum text Notizen }
Anreden {
int AnredeID PK
string Anrede
}
Titel {
int TitelID PK
string Titel
int TitelPositionID FK
}
TitelPositionen {
int TitelPositionID PK
string Position
}
%% ========================================
%% FIRMEN
%% ========================================
Firmen {
int FirmaID PK
string Firmenname
int RechtsformID FK
int BrancheID FK
}
Rechtsformen {
int RechtsformID PK
string Rechtsform
}
Branchen {
int BrancheID PK
string Branche
}
Kontakt_Firma {
int Kontakt_FirmaID PK
int KontaktID FK
int FirmaID FK
int PositionID FK
date von_Datum
date bis_Datum
}
Positionen {
int PositionID PK
string Positionsbezeichnung
}
%% ========================================
%% ADRESSEN & ORTE
%% ========================================
Adressen {
int AdresseID PK
int StrasseID FK
string Hausnummer
string HausnummerZusatz
int AdresszusatzID FK
int PLZID FK
int AdressTypID FK
}
Strassen {
int StrasseID PK
string Strassenname
int OrtID FK
}
PLZ {
int PLZID PK
string PLZ
int OrtID FK
}
Orte {
int OrtID PK
string Ortsname
int RegionID FK
}
Regionen {
int RegionID PK
string Regionsname
int LandID FK
}
Laender {
int LandID PK
string Laendername
string ISO2
string ISO3
string Laendervorwahl
int WaehrungID FK
}
Waehrungen {
int WaehrungID PK
string Waehrung
string ISO_Code
string Symbol
}
Adresszusaetze {
int AdresszusatzID PK
string Zusatz
}
AdressTypen {
int AdressTypID PK
string Typ
}
Kontakt_Adresse {
int Kontakt_AdresseID PK
int KontaktID FK
int AdresseID FK
bool IstHauptadresse
date Gueltig_von
date Gueltig_bis
}
Firma_Adresse {
int Firma_AdresseID PK
int FirmaID FK
int AdresseID FK
bool IstHauptsitz
date Gueltig_von
date Gueltig_bis
}
%% ========================================
%% TELEFON
%% ========================================
Telefonnummern {
int TelefonID PK
int LaendervorwahlID FK
string Ortsvorwahl
string Rufnummer
string Durchwahl
int TelefonTypID FK
}
Laendervorwahlen {
int LaendervorwahlID PK
string Vorwahl
int LandID FK
}
TelefonTypen {
int TelefonTypID PK
string Typ
}
Kontakt_Telefon {
int Kontakt_TelefonID PK
int KontaktID FK
int TelefonID FK
bool IstHauptnummer
date Gueltig_von
date Gueltig_bis
}
Firma_Telefon {
int Firma_TelefonID PK
int FirmaID FK
int TelefonID FK
string Abteilung
date Gueltig_von
date Gueltig_bis
}
%% ========================================
%% E-MAIL
%% ========================================
EMail_Adressen {
int EmailID PK
string EmailAdresse
int EmailTypID FK
}
EmailTypen {
int EmailTypID PK
string Typ
}
Kontakt_Email {
int Kontakt_EmailID PK
int KontaktID FK
int EmailID FK
bool IstHauptemail
date Gueltig_von
date Gueltig_bis
}
Firma_Email {
int Firma_EmailID PK
int FirmaID FK
int EmailID FK
string Abteilung
date Gueltig_von
date Gueltig_bis
}
%% ========================================
%% WEBSITES
%% ========================================
Websites {
int WebsiteID PK
string URL
int WebsiteTypID FK
}
WebsiteTypen {
int WebsiteTypID PK
string Typ
}
Kontakt_Website {
int Kontakt_WebsiteID PK
int KontaktID FK
int WebsiteID FK
}
Firma_Website {
int Firma_WebsiteID PK
int FirmaID FK
int WebsiteID FK
}
%% ========================================
%% BANKING
%% ========================================
Bankverbindungen {
int BankverbindungID PK
string IBAN
string BIC
int BankID FK
}
Banken {
int BankID PK
string Bankname
string BLZ
int LandID FK
}
Kontakt_Bankverbindung {
int Kontakt_BankverbindungID PK
int KontaktID FK
int BankverbindungID FK
bool IstHauptkonto
}
Firma_Bankverbindung {
int Firma_BankverbindungID PK
int FirmaID FK
int BankverbindungID FK
}
%% ========================================
%% STEUERN
%% ========================================
Steuer_IDs {
int SteuerID_TableID PK
string Nummer
int SteuerTypID FK
}
SteuerTypen {
int SteuerTypID PK
string Typ
int LandID FK
}
Kontakt_SteuerID {
int Kontakt_SteuerID_ID PK
int KontaktID FK
int SteuerID_TableID FK
}
Firma_SteuerID {
int Firma_SteuerID_ID PK
int FirmaID FK
int SteuerID_TableID FK
}
%% ========================================
%% BEZIEHUNGEN
%% ========================================
Beziehungen {
int BeziehungID PK
int KontaktID_1 FK
int KontaktID_2 FK
int BeziehungsTypID FK
date seit_Datum
}
BeziehungsTypen {
int BeziehungsTypID PK
string Typ
}
%% ========================================
%% SPRACHEN
%% ========================================
Kommunikationssprachen {
int KommunikationsspracheID PK
int KontaktID FK
int FirmaID FK
int SpracheID FK
int SprachlevelID FK
}
Sprachen {
int SpracheID PK
string Sprache
string ISO_Code
}
Sprachlevel {
int SprachlevelID PK
string Level
}
%% ========================================
%% TAGS
%% ========================================
Tags {
int TagID PK
string Tagname
int TagKategorieID FK
}
TagKategorien {
int TagKategorieID PK
string Kategoriename
}
Kontakt_Tag {
int Kontakt_TagID PK
int KontaktID FK
int TagID FK
}
Firma_Tag {
int Firma_TagID PK
int FirmaID FK
int TagID FK
}
%% ========================================
%% BEZIEHUNGEN (RELATIONSHIPS)
%% ========================================
%% Kontakte
Kontakte ||--o{ Anreden : "hat"
Kontakte ||--o{ Titel : "hat"
Titel ||--o{ TitelPositionen : "hat"
%% Firmen
Firmen ||--o{ Rechtsformen : "hat"
Firmen ||--o{ Branchen : "hat"
Kontakte ||--o{ Kontakt_Firma : "arbeitet bei"
Firmen ||--o{ Kontakt_Firma : "beschäftigt"
Kontakt_Firma ||--o{ Positionen : "in Position"
%% Adressen
Adressen ||--o{ Strassen : "liegt in"
Adressen ||--o{ PLZ : "hat"
Adressen ||--o{ Adresszusaetze : "hat"
Adressen ||--o{ AdressTypen : "vom Typ"
Strassen ||--o{ Orte : "in"
PLZ ||--o{ Orte : "gehört zu"
Orte ||--o{ Regionen : "in"
Regionen ||--o{ Laender : "in"
Laender ||--o{ Waehrungen : "hat"
Kontakte ||--o{ Kontakt_Adresse : "hat"
Adressen ||--o{ Kontakt_Adresse : "zugeordnet"
Firmen ||--o{ Firma_Adresse : "hat"
Adressen ||--o{ Firma_Adresse : "zugeordnet"
%% Telefon
Telefonnummern ||--o{ Laendervorwahlen : "hat"
Telefonnummern ||--o{ TelefonTypen : "vom Typ"
Laendervorwahlen ||--o{ Laender : "gehört zu"
Kontakte ||--o{ Kontakt_Telefon : "hat"
Telefonnummern ||--o{ Kontakt_Telefon : "zugeordnet"
Firmen ||--o{ Firma_Telefon : "hat"
Telefonnummern ||--o{ Firma_Telefon : "zugeordnet"
%% E-Mail
EMail_Adressen ||--o{ EmailTypen : "vom Typ"
Kontakte ||--o{ Kontakt_Email : "hat"
EMail_Adressen ||--o{ Kontakt_Email : "zugeordnet"
Firmen ||--o{ Firma_Email : "hat"
EMail_Adressen ||--o{ Firma_Email : "zugeordnet"
%% Websites
Websites ||--o{ WebsiteTypen : "vom Typ"
Kontakte ||--o{ Kontakt_Website : "hat"
Websites ||--o{ Kontakt_Website : "zugeordnet"
Firmen ||--o{ Firma_Website : "hat"
Websites ||--o{ Firma_Website : "zugeordnet"
%% Banking
Bankverbindungen ||--o{ Banken : "bei"
Banken ||--o{ Laender : "in"
Kontakte ||--o{ Kontakt_Bankverbindung : "hat"
Bankverbindungen ||--o{ Kontakt_Bankverbindung : "zugeordnet"
Firmen ||--o{ Firma_Bankverbindung : "hat"
Bankverbindungen ||--o{ Firma_Bankverbindung : "zugeordnet"
%% Steuern
Steuer_IDs ||--o{ SteuerTypen : "vom Typ"
SteuerTypen ||--o{ Laender : "in"
Kontakte ||--o{ Kontakt_SteuerID : "hat"
Steuer_IDs ||--o{ Kontakt_SteuerID : "zugeordnet"
Firmen ||--o{ Firma_SteuerID : "hat"
Steuer_IDs ||--o{ Firma_SteuerID : "zugeordnet"
%% Beziehungen zwischen Kontakten
Kontakte ||--o{ Beziehungen : "hat Beziehung zu"
Beziehungen ||--o{ BeziehungsTypen : "vom Typ"
%% Sprachen
Kommunikationssprachen ||--o{ Sprachen : "spricht"
Kommunikationssprachen ||--o{ Sprachlevel : "auf Level"
Kontakte ||--o{ Kommunikationssprachen : "spricht"
Firmen ||--o{ Kommunikationssprachen : "verwendet"
%% Tags
Tags ||--o{ TagKategorien : "in Kategorie"
Kontakte ||--o{ Kontakt_Tag : "hat"
Tags ||--o{ Kontakt_Tag : "zugeordnet"
Firmen ||--o{ Firma_Tag : "hat"
Tags ||--o{ Firma_Tag : "zugeordnet"
…
KI-gestützte Datensatzerstellung in FileMaker: Als AddOn installierbar
KI-gestützte Datensatzerstellung in FileMaker: Wenn Sprache zu Daten wird !!! (Das System wird als AddOn in ein bestehendes FileMaker-System integriert)

Das Problem Jeder FileMaker-Entwickler kennt es: Daten erfassen ist mühsam. Besonders wenn Mitarbeiter unterwegs sind, offline arbeiten oder einfach keine Lust haben, Dutzende von Feldern auszufüllen. Was wäre, wenn man einfach sagen könnte:
“Erstelle einen Auftrag für Pumpe austauschen bei Anlage 2666, Status in Planung, Kategorie Reparatur, im Mai, mit Notiz und Aufgabe für 3 Mitarbeiter” Und das System erstellt automatisch: ✅ Den Master-Datensatz (Auftrag) ✅ Verknüpfte Notizen ✅ Tasks mit Fristen ✅ Automatische Verknüpfungen zu bestehenden Objekten ✅ Alle Felder korrekt befüllt Genau das haben wir gebaut.
Die Lösung: Ein intelligentes KI-Bridge-System Wir haben eine PHP-basierte Middleware entwickelt, die als Brücke zwischen FileMaker und Claude AI (Anthropic) funktioniert. Das Besondere: Das System ist vollständig konfigurierbar über FileMaker, ohne eine Zeile Code zu ändern. Die 3 Kern-Innovationen:
- Dynamisches Config-System Statt statischer Workflows werden alle Konfigurationen als JSON in FileMaker gepflegt: Welche Layouts verwendet werden Welche Felder verfügbar sind Welche Item-Typen (Notizen, Tasks, etc.) erstellt werden sollen Spezielle Anweisungen für die KI Diese Configs werden automatisch auf dem Server gespeichert und können von jedem Mitarbeiter wiederverwendet werden.
- Intelligente Config-Auswahl Das Geniale: Mitarbeiter müssen keine Config-ID mehr angeben. Das System analysiert ihren Text-Prompt automatisch:

Prompt: “Erstelle einen neuen Auftrag…” → System findet automatisch Config “Auftrag anlegen” → Lädt passende Feldnamen & Layouts → Führt aus

Über ein Keyword-Scoring-System werden Prompts mit gespeicherten Configs abgeglichen. Je mehr Keywords übereinstimmen, desto höher der Score. 3. Such- & Verknüpfungs-Engine Nicht nur Erstellen, auch Suchen! Das System kann: In bestehenden FileMaker-Datensätzen suchen (z.B. Anlage 2666) Relevante IDs extrahieren Automatisch mit neuen Datensätzen verknüpfen

Technische Highlights Intelligentes Field-Mapping Claude AI kennt FileMaker nicht. Aber unser System: Ruft dynamisch verfügbare Felder aus dem FileMaker-Layout ab Sendet sie als Prompt an Claude Claude befüllt nur existierende Felder Case-insensitive Matching (project_name → Project_Name) Automatische Datumskonvertierung (verschiedene Formate → FileMaker-Format) Filterung von AutoEnter/Calculation-Feldern
Multi-Item-Support Ein Prompt kann mehrere Aktionen auslösen:
{ “master”: “Auftrag erstellen”, “items”: [ “Notiz anlegen”, “Task anlegen”, “Objekt zuordnen” ] } Jedes Item kann erstellen oder suchen – automatisch erkannt anhand von Keywords wie “zuordnen”, “verknüpfen”, “finde”.
Das gibt der Mitarbeiter an: Erstelle einen neuen Auftrag und die Notiz -Teste mal die 1372- Der Auftragsname lautet Pumpe ist bald defekt und muss getauscht werden. Der Status lautet -In Planung-, die Kategorie heisst -Reparatur- Als Planungsmonat hinterlege den Mai. Die Anlage ist die 2666. Erstelle auch gleich eine Aufgabe dazu. Hinterlege das Product bzw. Objekt dazu. Für den Auftrag werden 3 Mitarbeiter benötigt.
Prominente Prompt-Hierarchie FileMaker-User können spezielle Anweisungen mitgeben: 🎯 SPEZIELLE ANWEISUNGEN FÜR DEN MASTER:────────────────────────────────────────Planungsmonat immer als 12/2025 formatieren.Anlagennummer in Feld id_anlage eintragen.────────────────────────────────────────BEACHTE DIESE ANWEISUNGEN STRIKT! Diese werden Claude mit visueller Betonung präsentiert, sodass sie nicht übersehen werden.
Use Cases aus der Praxis Szenario 1: Außendienst (Offline-First) Problem: Techniker ist vor Ort, kein Internet, notiert sich 10 Aufträge handschriftlich. Mit unserem System: Notizen in FMGo-App erfassen (offline) Bei Internet: Alle Prompts auf einmal absenden System erstellt automatisch alle Aufträge mit Notizen, Tasks, Verknüpfungen Techniker muss keine Felder ausfüllen Szenario 2: Multi-CRM Umgebung Problem: Firma hat mehrere CRM-Systeme (Vertrieb, Service, Projekte). Mit unserem System: Configs: crm_vertrieb_firma, service_auftrag, projekt_anlegen Automatische Config-Erkennung je nach Prompt Ein System, mehrere Workflows Szenario 3: Sprachbarriere Problem: Internationale Teams, verschiedene Sprachen. Mit unserem System: Prompts in jeder Sprache möglich (Claude versteht 95+ Sprachen) FileMaker-Feldnamen bleiben gleich Nur die Config-Bezeichnung anpassen
Performance & Kosten Geschwindigkeit Config-Laden: < 50ms (lokales JSON) Claude API: ~2-4 Sekunden (abhängig von Komplexität) FileMaker API: ~500ms pro Record Gesamt: 3-5 Sekunden für komplette Workflow-Ausführung API-Kosten (Claude Haiku) Input: ~$0.00025 pro 1K Tokens Output: ~$0.00125 pro 1K Tokens Durchschnitt: ~$0.01-0.03 pro Prompt → Selbst bei 1000 Prompts/Tag: ~$10-30/Monat
Sicherheit & Datenschutz ✅ Kein Datenleck: Nur Feldnamen (nicht Werte) werden im Prompt sichtbar ✅ Verschlüsselte Verbindung: HTTPS zu Claude API ✅ On-Premise möglich: Bei Bedarf mit lokaler AI (z.B. Ollama) ✅ Config-Zugriffskontrolle: FileMaker-Berechtigungen greifen
Technik: Frontend: FileMaker Pro/Go Middleware: PHP 8.x (FileMaker Data API + Anthropic API) AI: Claude 3 Haiku (Anthropic) Storage: JSON-Configs (dateisystembasiert)
FM MailBridge ist da, E-Mails direkt in FileMaker integrieren

Ab sofort verfügbar: FM MailBridge, das Add-on für alle, die E-Mails nahtlos in ihre FileMaker-Lösungen einbinden möchten ohne externe Tools, ohne manuelle Umwege, direkt per IMAP.
Ob als Einzelplatzversion, für den Servereinsatz oder als Entwicklerlizenz zur Weiterverwertung in eigenen Projekten. FM MailBridge macht es möglich, E-Mails automatisiert in deine FileMaker-Umgebung zu integrieren. Übersichtlich, effizient und vollständig anpassbar.
Was ist FM MailBridge?
FM MailBridge ist ein eigenständiges PHP-basiertes Modul, das sich direkt mit IMAP-Postfächern verbindet und E-Mails samt Anhängen strukturiert an FileMaker übergibt. Dieses erfolgt via Insert from URL. Dabei wird der komplette Mailinhalt als JSON übergeben: Absender, Betreff, Datum, Text (wahlweise HTML oder nur Text) und wenn vorhanden, Base64-kodierte Anhänge inkl. Dateiname und MIME-Typ.
Die Integration ist so konzipiert, dass sie in beliebige FileMaker-Projekte eingebaut werden kann. Entweder lokal, serverseitig oder als Bestandteil einer kommerziellen Lösung.
Drei Lizenzmodelle für jeden Anwendungsfall:
-
Einzelplatz Für den lokalen Abruf durch einen Entwickler oder Einzelplatznutzer. Einrichtung über lokalen Webserver. -49 €
-
Server Für den zentralen Einsatz auf einem FileMaker Server (mit Zeitplan oder PSOS). Keine Client-Einrichtung nötig. -199 €
-
Enterprise Für Entwickler und Agenturen, die FM MailBridge in eigene FileMaker-Projekte einbauen und weiterverkaufen möchten. -699 €
Was macht FM MailBridge besonders?
• Nutzt reinen IMAP-Zugriff, keine Google API oder OAuth erforderlich
• Funktioniert mit Gmail, Outlook, Webhostern u. v. m.
• Übergibt Mails strukturiert als JSON (inkl. Anhänge)
• Vollständig anpassbar für beliebige FileMaker-Lösungen
• Keine externen Tools nötig, nur PHP & FileMaker
Technischer Hintergrund
Die Kommunikation erfolgt über ein kompaktes PHP-Skript, das IMAP-Mails abruft, verarbeitet und als JSON zurückliefert. FileMaker verarbeitet diese Daten direkt innerhalb der eigenen Tabellen-Strucktur. Der Aufbau ist stabil, getestet mit tausenden E-Mails und bewusst schlank gehalten.
Produktseite & Download: https://filemaker-experts.de/application.html
Fragen zur Integration, Lizenz oder Sonderfällen? Schreib uns an: support@filemaker-experts.de
E-Mails per IMAP auslesen und an FileMaker übergeben -Ohne Plugin-
In vielen FileMaker-Projekten stellt sich irgendwann die Frage: Wie integriere ich eingehende E-Mails samt Anhängen möglichst flexibel in meine Lösung? Besonders dann, wenn keine Drittanbieter-Dienste gewünscht sind und alles unter eigener Kontrolle laufen soll. In einem aktuellen Projekt habe ich genau das umgesetzt, mit einer simplen, robusten Lösung per PHP und IMAP, die hervorragend mit FileMaker zusammenspielt.

Zielsetzung
Das System soll eingehende E-Mails (z. B. aus einem Support-Postfach) auslesen, alle relevanten Felder wie Betreff, Absender, Datum, Text und Anhänge verarbeiten und die Informationen strukturiert an FileMaker übergeben. Das ganze in einem JSON-Format, das sofort weiterverarbeitet werden kann.
Technischer Aufbau
Die zentrale Komponente ist ein PHP-Skript, das per imap_open() auf das Postfach zugreift und wahlweise alle oder nur ungelesene Mails verarbeitet. Um die Performance zu schonen, wird beim ersten Abruf ein Zeitraum (z. B. 30 Tage) berücksichtigt, danach nur noch UNSEEN-Mails. Das Format der zurückgegebenen Daten ist JSON.
[
{
"uid": 542,
"subject": "Neuer Auftrag",
"from": "info@kunde.de",
"date": "2025-07-10 09:22:00",
"body": "Anbei unser Auftrag...",
"attachments": [
{
"filename": "auftrag.pdf",
"mime_type": "application/pdf",
"size": 18320,
"content": "JVBERi0xLjQKJ...(Base64)",
"disposition": "attachment",
"url": "[meine-domain.de/mailanhan...](https://meine-domain.de/mailanhang/auftrag.pdf)"
}
]
}
]
Diese Daten werden dann einfach verarbeitet. In meinem ersten test ist nur ein Anhang möglich, allerdings ist die Anpassung innerhalb von FileMaker nur mit geringem Aufwand verbunden. Um die Verarbeitung von Anhängen so einfach wie möglich zu gestalten, werden die Mail-Anhänge auf dem Server gespeichert. Per JSON wird wie ersichtlich die URL zurückgeliefert. Somit ist es im Anschluss des Skriptes innerhalb von FileMaker möglich, die Dateien in FM-Containern zu speichern.
# MailAbruf in file Mail # # Aus URL einfügen [ Auswahl ; Mit Dialog: Aus ; Ziel: $$MAIL_JSON ; "[deine](https://deine)_url_test.de/cap/imap_fetch_mails.php" ] # Variable setzen [ $anzahl ; Wert: ElementeAnzahl ( JSONListKeys ( $$MAIL_JSON ; "" ) ) ] Variable setzen [ $json ; Wert: $$MAIL_JSON ] # # Variable setzen [ $i ; Wert: 0 ] # Schleife (Anfang) [ Flush: Immer ] Verlasse Schleife wenn [ $i ≥ $anzahl ] Variable setzen [ $uid ; Wert: JSONGetElement ( $json ; "[" & $i & "].uid" ) ] Variable setzen [ $subject ; Wert: JSONGetElement ( $json ; "[" & $i & "].subject" ) ] Variable setzen [ $from ; Wert: JSONGetElement ( $json ; "[" & $i & "].from" ) ] Variable setzen [ $date ; Wert: JSONGetElement ( $json ; "[" & $i & "].date" ) ] Variable setzen [ $body ; Wert: JSONGetElement ( $json ; "[" & $i & "].body" ) ] Variable setzen [ $mime ; Wert: JSONGetElement ( $json ; "[" & $i & "].mime_type" ) ] Variable setzen [ $mime_type ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].mime_type" ) ] # # Verarbeitung der Anhänge Variable setzen [ $anzahl_anhang ; Wert: ElementeAnzahl ( JSONListKeys ( $json ; "[" & $i & "].attachments" ) ) ] Wenn [ $anzahl_anhang > 0 ] Variable setzen [ $anhang_filename ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].filename" ) ] Variable setzen [ $anhang_base64 ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].base64" ) ] Variable setzen [ $mime_type ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].mime_type" ) ] Variable setzen [ $anhang_url ; Wert: JSONGetElement ( $json ; "[" & $i & "].attachments[0].url" ) ] Ende (wenn) # # # # # Datensatz anlegen Neuer Datensatz/Abfrage Feldwert setzen [ Mails::uid ; $uid ] Feldwert setzen [ Mails::subject ; $subject ] Feldwert setzen [ Mails::from ; $from ] Feldwert setzen [ Mails::date ; $date ] Feldwert setzen [ Mails::body ; $body ] Feldwert setzen [ Mails::anhang_filename ; $anhang_filename ] Feldwert setzen [ Mails::anhang_base64 ; $anhang_base64 ] Feldwert setzen [ Mails::anhang_mime_typ ; $mime_type ] # Datei als Anhang nach FileMaker Variable setzen [ $base64 ; Wert: Mails::anhang_base64 ] Variable setzen [ $mime ; Wert: Mails::anhang_mime_typ ] Variable setzen [ $name ; Wert: Mails::anhang_filename ] # Data URL vorbereiten Feldwert setzen [ Mails::anhang_url ; $anhang_url ] Aus URL einfügen [ Auswahl ; Mit Dialog: Aus ; Ziel: Mails::anhang_container ; Mails::anhang_url ] Variable setzen [ $i ; Wert: $i + 1 ] # Nun den Dateianhang wieder löschen Variable setzen [ $deleteURL ; Wert: "[deine](https://deine)_url_test.de/cap/delete_attachment.php?file=" &Mails::anhang_filename ] Scriptpause setzen [ Dauer (Sekunden): 1 ] Aus URL einfügen [ Auswahl ; Mit Dialog: Aus ; Ziel: $$ANTWORT ; $deleteURL ] Schleife (Ende)
Um nicht die Anhänge längerfristig auf dem Server zu speichern, wird nach einer Scriptpause, ein weiteres PHP-Script aufgerufen. Dieses löscht den Anhang und stellt somit sicher, das dieser nicht über eine URL sichtbar gemacht werden kann.

Diese Lösung ist ideal für FileMaker-Projekte, bei denen volle Kontrolle über das E-Mail-System gewünscht ist. Sie erfordert kein IMAP-Plugin, kein MBS, keine externen Dienste und ist vollständig serverbasiert. Alles steuerbar über einfache URL-Aufrufe. Der Abruf von E-Mails wird so zum automatisierten Teil des Workflows, vom Posteingang bis zur direkten Weiterverarbeitung in FileMaker.
Mein Artikel ist im FileMaker Magazin erschienen!
Nun noch das aktuelle PDF als Auszug aus dem Magazin.
Mein Artikel ist im FileMaker Magazin erschienen!
Mein Artikel ist im FileMaker Magazin erschienen!

Ich zeige darin, wie man eine sequentielle Suche mit PHP und FileMaker umsetzen kann. Eine Lösung, die auch bei großen Datenmengen performant bleibt.
Die Idee entstand, als ein bestehender Ansatz bei einem Kunden plötzlich ins Stocken geriet. Statt den Suchprozess in FileMaker zu quälen, habe ich den Fokus verlagert: -Export per CSV, -Suche in PHP, -Rückgabe der IDs per fmp://URL – und das alles ohne Plugins oder externe Datenbank.
Highlights aus dem Artikel: • FileMaker-Export als Tab-getrennte Datei • Upload via Insert from URL und cURL • serverseitige Verarbeitung mit PHP • blitzschnelle Filterung im WebViewer • Rückübergabe der gefundenen IDs an FileMaker • robust, portabel und unabhängig von der Datenstruktur
Jetzt nachzulesen im FileMaker Magazin, Ausgabe 07/2025: „Sequentielle Suche – Arbeitsteilung zwischen FileMaker und PHP“ (von Ronny Schrader | MaRo-Programmierung GbR)
Wer Interesse an der Lösung oder einer Demo-Datei hat, darf sich gern bei mir melden.
Kalender mit FileMaker und PHP
Viele Jahre nutze ich nun in FileMaker das Kalendermodul von “Otmar Kramis”. Ein wunderschönes aber extrem komplexes Modul um Kalenderdaten innerhalb von FileMaker in einem WebViewer darstellen zu können. Umfangreiche Berechnungen machen die Einbindung oftmals wenn auch nicht unmöglich, so doch recht schwierig und aufwendig. Deshalb habe ich mich entschlossen etwas schnelles und sehr agiles zu entwickeln. Heraus gekommen ist ein schöner Kalender, mit dynamisch geladenen Daten.

Die Kartenansichten gibt es natürlich auch in iPad-Format

Für die Nutzung am iPhone gibt es auch eine angepasste Version

Die Umsetzung erfolgte mit FileMaker, PHP und JavaScript.
Fensterpositionen automatisch speichern & wiederherstellen

Beim Arbeiten mit FileMaker kann es sinnvoll sein, Fensterpositionen und -größen zu speichern, damit sich Fenster beim erneuten Öffnen an derselben Stelle befinden. In diesem Beitrag zeige ich, wie das mit einer Tabelle zur Speicherung der Fensterpositionen und einem Skript-Trigger umgesetzt wird. Das Problem bestand darin, es öffnet sich ein Fenster, aus diesem Fenster wieder ein Fenster. Das ganze wird überlagert. Aber eigentlich benötigt der Kunde alle Informationen sichtbar, verteilt über mehrere Bildschirme.
Die Umsetzung, recht einfach und der Zeitaufwand hält sich in Grenzen. Ich lege eine Tabelle an, diese muss nicht referenziert sein. Einfach -FEN_Fensterposition-, FileMaker legt freundlicherweise ja auch gleich ein passendes Layout an. Ich habe hinterlegt Spalten für:
- FensterLinks -Hole (FensterLinks)
- FensterOben -Hole (FensterOben)
- FensterBreite -Hole (FensterBreite)
- FensterHoehe. -Hole (FensterHoehe)
- UserName -Hole (ProgrammBenutzerName)
- id_fenster -Hole ( LayoutNummer )
Wir starten per SriptTrigger jeweils das gleiche Script, übergeben einmal den Parameter -close-, bei Layout Verlassen, einmal bei Datensatz laden, per Parameter -open-.
Am Anfang des Sciptes setzen wir alle benötigten Variablen. Dann öffnen wir ein Fenster mit der Tabelle FEN_Fensterposition bei 1x1 Pixel bei -30000 x -30000. Also für den Prozess unsichtbar. Wenn der Parameter -open- gesetzt ist, gehen wir und suchen nach der Layout-ID und dem User. Wird ein Datensatz gefunden, setzen wir die Feldwerte in Variablen und nutzen den Befehl -Fensterposition/größe ändern. Allerdings erst nachdem wir unser Arbeitsfenster für die Suche geschlossen haben. Wird ein Datensatz gefunden, verschiebt sich das Fenster in die angegebene Position. Gibt es keinen gefundenen Datensatz, bleibt das Fenster wie geöffnet.
Kommt über den Trigger der Wert -close-, arbeiten wir in ähnlicher Form. Wir suchen nach der Fenster_ID und dem User. Wird diesmal kein Datensatz gefunden, dann wird ein neuer Datensatz erstellt und die Werte der Position werden eingetragen. Wird ein Datensatz gefunden, werden die Positionsdaten überschrieben.
Das ganze ist einfach umzusetzen und im Handling, da keine Referenzen notwendig sind, sehr schnell zu implementieren.
Große Datenmengen performant aus FileMaker übertragen und anzeigen – ohne Wartezeit

In FileMaker große Datenmengen zu verarbeiten, kann schnell zu Performance-Problemen führen. Besonders wenn FileMaker noch im Hintergrund sortiert oder aggregiert, kann die Benutzeroberfläche einfrieren oder es dauert mehrere Sekunden, bis die Daten sichtbar sind. Das Problem stellt sich immer wieder bei Altlösungen die 10 oder 20 Jahre alt sind. Häufig sind diese Datenbanken bis ins kleinste an die Kunden-Prozesse angepasst. Ein Neubau unrealistisch bis unbezahlbar. Performance-Probleme nur in den langen Listenansichten mit Unmengen an Datensätzen, diese dann noch mit Sortierungen und Formelfeldern.
Doch es gibt eine Möglichkeit, Daten sofort anzuzeigen, auch wenn FileMaker noch weiterarbeitet: Daten per POST an einen WebViewer übergeben und dort asynchron anzeigen.
Warum nicht einfach FileMaker-Listen?
Standardmäßig lädt FileMaker Listenansichten synchron – das heißt, es wartet, bis alle Datensätze verarbeitet sind. Das führt zu Problemen, wenn: • Tausende Datensätze geladen werden, • FileMaker noch sortiert, • eine Suche viele Treffer hat, • Zusatzinformationen aus mehreren Tabellen geladen werden müssen.
Die Lösung: Daten mit -X POST effizient an eine externe Webanwendung übergeben und dort direkt rendern – unabhängig davon, ob FileMaker noch weiter rechnet.
Datenübergabe aus FileMaker: So geht’s richtig
Wir nutzen den Insert from URL-Befehl, um die Daten per POST an eine Webanwendung zu übergeben. Hierbei setzen wir auf application/x-www-form-urlencoded, da diese Methode stabil mit großen Datenmengen arbeitet.
Set Variable [ $url ; Value: "http://meinserver.de/daten.php" ]
Set Variable [ $payload ; Value:
"projects=" & $id_projects &
"&staff=" & $id_staff &
"&anlage=" & $anlage &
"&status=" & $status &
"&task=" & $id_task &
"&image=" & $image &
"&inhalt=" & $inhalt &
"&historyColors=" & $historyColors &
"&planungsmonat=" & $planungsmonat &
"&date_von=" & $date_von &
"&date_bis=" & $date_bis &
"&zeit_von=" & $zeit_von &
"&zeit_bis=" & $zeit_bis &
"&anzahl_staff=" & $anzahl_staff &
"&staff2=" & $id_staff_2 &
"&staff3=" & $id_staff_3 &
"&erstellt=" & $erstellt &
"&prio=" & $prio &
"¬es=" & $notes
]
Insert from URL [
$url ;
"-X POST " &
"--header \"Content-Type: application/x-www-form-urlencoded\" " &
"--data " & Zitat ( $payload )
]
Der Vorteil, ich kann unabhängig von URL-Begrenzungen Daten übergeben, ich erspare mir den Aufbau komplexer JSON-Strukturen innerhalb von FileMaker. Datentrennung geschieht bei mir vorzugsweise mit einem Pipe. Es ist natürlich auch anderes möglich. Datensammlung innerhalb von FileMaker über Schleifen, das verspricht bessere Kontrolle oder wenn es mal schnell gehen soll, geht natürlich auch die List-Funktion. Das ist aber Geschmacksache.
Unser PHP-Script empfängt die Daten und kann mit der Verarbeitung beginnen. Sobald die Daten per POST an PHP gesendet wurden, werden sie in einzelne Arrays zerlegt, sodass sie flexibel weiterverarbeitet werden können. Durch das entdecken von Strings anhand eines Trennzeichens (z. B. |) lassen sich in einer einzigen Anfrage übertragen:
$projects = isset($_POST['projects']) ? explode('|', $_POST['projects']) : [];
$staff = isset($_POST['staff']) ? explode('|', $_POST['staff']) : [];
$anlage = isset($_POST['anlage']) ? explode('|', $_POST['anlage']) : [];
$status = isset($_POST['status']) ? explode('|', $_POST['status']) : [];
$task = isset($_POST['task']) ? explode('|', $_POST['task']) : [];
$image = isset($_POST['image']) ? explode('|', $_POST['image']) : [];
$inhalt = isset($_POST['inhalt']) ? explode('|', $_POST['inhalt']) : [];
$planungsmonat = isset($_POST['planungsmonat']) ? explode('|', $_POST['planungsmonat']) : [];
Die Daten aus PHP werden dann über eine Schleife in HTML überführt. In diesem Beispiel erzeugen wir eine dynamische Tabelle, die aus den übergebenen Daten generiert wird:
<table border="1">
<tr>
<th>Projekt</th>
<th>Aufgabe</th>
<th>Mitarbeiter</th>
<th>Status</th>
</tr>
<?php foreach ($task as $index => $taskName): ?>
<tr>
<td><?= htmlspecialchars($projects[$index] ?? 'Unbekannt') ?></td>
<td><?= htmlspecialchars($taskName) ?></td>
<td><?= htmlspecialchars($staff[$index] ?? 'Kein Mitarbeiter') ?></td>
<td><?= htmlspecialchars($status[$index] ?? 'Unbekannt') ?></td>
</tr>
<?php endforeach; ?>
</table>
Mit ein wenig CSS kann die Liste angepasst werden, Zwischesortierungen, Statusfarben, nichts was nicht möglich ist.
.task-list { width: calc(100% - 20px); /* Verhindert das Überlaufen nach rechts / max-width: 100%; margin: 10px auto; background: white; padding: 10px; border-radius: 5px; box-shadow: 0px 0px 5px rgba(0, 0, 0, 0.2); font-size: 14px; overflow-x: hidden; / Falls nötig, um Überlauf zu vermeiden */ }
.task-group {
margin-top: 15px;
padding: 8px;
background: #3773B5;
font-size: 14px;
font-weight: bold;
color: white;
border-radius: 5px;
text-align: left;
}
.task-item {
width: 98%; /* Damit es nicht über den Container hinausragt */
max-width: 100%;
display: flex;
align-items: center;
justify-content: space-between;
padding: 5px 10px;
border-radius: 3px;
box-shadow: 1px 1px 3px rgba(0, 0, 0, 0.1);
font-size: 13px;
line-height: 1.2;
background-color: white;
flex-wrap: wrap;
box-sizing: border-box; /* Sorgt dafür, dass Padding berücksichtigt wird */
}
Eine sequentielle Suche, die in ihrer Schnelligkeit niemals in FileMaker abzubilden ist, runden die Tabelle ab.
<script>
document.getElementById("taskSearch").addEventListener("keyup", function() {
let searchQuery = this.value.toLowerCase();
let taskGroups = document.querySelectorAll(".task-group-container");
let resultCount = 0; // Zähler für die Anzahl der gefundenen Datensätze
taskGroups.forEach(group => {
let hasMatch = false;
let tasks = group.querySelectorAll(".task-item");
tasks.forEach(task => {
let text = task.innerText.toLowerCase(); // Gesamten Inhalt durchsuchen
if (text.includes(searchQuery)) {
task.style.display = ""; // Zeigen
hasMatch = true;
resultCount++; // Treffer zählen
} else {
task.style.display = "none"; // Verstecken
}
});
// Gruppe ausblenden, wenn keine Aufgabe übrig ist
group.style.display = hasMatch ? "" : "none";
});
// Anzeige der Trefferanzahl aktualisieren
document.getElementById("searchResultsCount").textContent = resultCount + " Ergebnisse gefunden";
});
</script>
Natürlich darf die Möglichkeit aus dem WebViewer heraus mit FileMaker zu kommunizieren nicht fehlen. In diesem Fall noch mit einer Bedingung.
document.addEventListener("DOMContentLoaded", function () {
document.querySelectorAll(".status-dropdown").forEach(function (dropdown) {
dropdown.addEventListener("change", function () {
let taskId = this.getAttribute("data-task-id");
let newStatus = this.value;
if (newStatus === "Angebot folgt") {
// PopOver anzeigen
let modal = document.getElementById("offerModal");
modal.style.display = "flex";
// Speichern-Button im PopOver
document.getElementById("confirmOffer").onclick = function () {
let priority = document.getElementById("offerPriority").value;
let note = document.getElementById("offerNote").value.trim();
if (note === "") {
alert(" Bitte eine Notiz eingeben!");
return;
}
modal.style.display = "none"; // Fenster schließen
// FileMaker-Skript aufrufen mit Priorität & Notiz
let fileMakerScriptURL = "fmp://$/AVAGmbH?script=UpdateTaskStatus¶m=" +
encodeURIComponent(taskId + "|" + newStatus + "|" + priority + "|" + note);
console.log(" FileMaker-Skript aufrufen:", fileMakerScriptURL);
window.location = fileMakerScriptURL;
};
// Abbrechen-Button im PopOver
document.getElementById("cancelOffer").onclick = function () {
modal.style.display = "none"; // Fenster schließen
dropdown.value = "In Planung"; // Status zurücksetzen
};
return; // Stoppe die normale Ausführung, solange PopOver offen ist
}
// Falls NICHT "Angebot folgt", normales Verhalten
let fileMakerScriptURL = "fmp://$/AVAGmbH?script=UpdateTaskStatus¶m=" +
encodeURIComponent(taskId + "|" + newStatus);
console.log("FileMaker-Skript aufrufen:", fileMakerScriptURL);
window.location = fileMakerScriptURL;
// Seite nach kurzer Verzögerung aktualisieren
setTimeout(function () {
window.location.reload();
}, 1000);
});
});
});
Es gibt unendliche Optimierungsmöglichkeiten. Das wichtigste ist aber, wir können mit recht wenig Aufwand, alte schwergewichtige FileMaker-Anwendungen wieder flott machen.
Teil Zwei der Kanban Entwicklung in FileMaker, Umstellung von GET auf POST
Die Evolution einer Kanban-Ansicht in FileMaker: Vom GET zum POST
In der kontinuierlichen Weiterentwicklung von Arbeitsprozessen und deren Darstellung in FileMaker ergibt sich oft die Notwendigkeit, bestehende Lösungen zu optimieren und an neue Anforderungen anzupassen. Genau dieser Gedanke begleitete die Entwicklung der Kanban-Ansicht, die sich ursprünglich auf GET-Parameter zur Datenübertragung stützte, nun aber auf POST umgestellt wurde. Ein scheinbar kleiner Wechsel, der jedoch große Auswirkungen hat – sowohl auf die Performance als auch auf die Flexibilität der Anwendung. Der wichtigste Aspekt, alle weiteren Daten die der Kunde jetzt in noch in den Kacheln sehen möchte, kann ich ohne Probleme übertragen. Ob 100 oder nur 50 Aufgaben. Das System benötigt keinerlei Vorfilterung innerhalb von FileMaker.
Ursprünglich wurde die Kanban-Ansicht über eine URL-basierte GET-Abfrage mit Daten versorgt. Die Vorteile lagen auf der Hand: einfache Implementierung, transparente Debugging-Möglichkeiten und eine schnelle Integration in den bestehenden Webviewer von FileMaker. Doch mit wachsendem Datenvolumen und steigenden Anforderungen an die übertragene Information stieß diese Methode an ihre Grenzen. Die maximale URL-Länge wurde zu einem Problem, und die Strukturierung komplexer Daten – insbesondere in Bezug auf Statusfarben, Aufträge und historische Änderungen – wurde zunehmend unübersichtlich.
Die logische Konsequenz war der Wechsel auf eine POST-Übertragung, die nicht nur größere Datenmengen bewältigen kann, sondern auch eine flexiblere Handhabung ermöglicht. Dabei stellte sich heraus, dass die Umstellung zwar in der Theorie simpel erschien, in der Praxis aber einige Herausforderungen mit sich brachte. FileMaker musste so konfiguriert werden, dass die Daten nicht mehr direkt als URL-Parameter übergeben wurden, sondern als strukturierte POST-Daten in die Webanwendung flossen. Das bedeutete, dass die gesamte Datenkette angepasst werden musste – von der Generierung der Werte in FileMaker über die Verarbeitung in PHP bis hin zur Darstellung im Webviewer.
Nach einigen Anpassungen und Tests zeigte sich schnell: Die POST-Methode brachte nicht nur eine sauberere und robustere Datenübertragung mit sich, sondern auch eine spürbare Verbesserung der Ladegeschwindigkeit. Während GET oft dazu führte, dass die URL unnötig aufgebläht wurde, ermöglicht POST eine strukturierte und sichere Übermittlung, die auch größere Datensätze problemlos verarbeitet. Gerade im Kontext eines Kanban-Boards mit zahlreichen Aufgaben, Statusänderungen und Nutzerinteraktionen ist das ein entscheidender Vorteil.
Ein besonders interessanter Nebeneffekt der Umstellung war die Vereinfachung der Datenstruktur. Während bei der GET-Variante viele Variablen direkt in der URL codiert und dekodiert werden mussten, erlaubt die POST-Methode eine klarere Trennung zwischen Client und Server. Die Farbmarkierungen, Statushistorien und Task-IDs ließen sich nun effizienter verarbeiten, und die Fehlersuche gestaltete sich deutlich angenehmer. Zudem eröffnete sich durch die Umstellung die Möglichkeit, noch weitere Daten ohne zusätzliche URL-Komplikationen zu übertragen – ein Schritt, der langfristig gesehen weitere Optimierungen ermöglichen wird.
Rückblickend zeigt diese Anpassung einmal mehr, wie wichtig es ist, Prozesse stetig zu hinterfragen und weiterzuentwickeln. Was gestern noch gut funktionierte, kann heute durch eine andere Herangehensweise erheblich verbessert werden. Die Migration von GET zu POST mag auf den ersten Blick nur eine technische Feinheit sein, doch in der Praxis trägt sie entscheidend zu einer performanten und skalierbaren Lösung bei. Die Kanban-Ansicht in FileMaker ist damit nicht nur flexibler, sondern auch zukunftssicherer geworden – und das ist letztlich das Ziel jeder guten Softwareentwicklung.
Der eigentliche Vorgang innerhalb von FileMaker ist klar. Sammeln der Daten per Schleife unter Beachtung der spezifischen Vorstellungen und Kundenwünsche. Das eigentlich interessante Prozedere, der Befehl aus URL einfügen.

 Angabe der URL mit dem Ziel der aufgerufenen PHP-Datei.
Angabe der URL mit dem Ziel der aufgerufenen PHP-Datei.
 Die cURL Eintragungen.
Die cURL Eintragungen.
 Das Endergebnis. Durch viele Tests etwas durcheinander. Grundsätzliche Farbmuster zum erkennen der im Zusammenhang stehende Aufgaben und auf der linken Seite der Kacheln befindet sich ein Farbmuster das den Verlauf durch die verschiedenen Status-Änderungen zeigt.
Das Endergebnis. Durch viele Tests etwas durcheinander. Grundsätzliche Farbmuster zum erkennen der im Zusammenhang stehende Aufgaben und auf der linken Seite der Kacheln befindet sich ein Farbmuster das den Verlauf durch die verschiedenen Status-Änderungen zeigt.
Heute habe ich das perfekte Beispiel, für das Gegenteil des Anker Bojen-Prinzip in die Hände bekommen. Mein Kunde hat sich eine wirklich tolle Datenbank gebaut, schnell, funktionell und recht nett anzuschauen. Nur in die Datenbankstruktur darf ich kaum schauen.
Die Struktur zeigt eine sehr komplexe und dicht miteinander verbundene Datenbankstruktur, die das genaue Gegenteil des Anker-Bojen-Prinzips in FileMaker darstellt. Es ist klar zu erkennen, wir erkennen nichts. Während das Anker-Bojen-Prinzip auf Modularität, Flexibilität und klare Beziehungen setzt, ist diese Struktur unübersichtlich und schwer nachvollziehbar. Hier sind die wesentlichen Merkmale und Probleme dieser Art von Struktur:
-
Unübersichtlichkeit und Komplexität • Die Datenbank ist überladen mit Beziehungen zwischen Tabellen, die sich über mehrere Ebenen hinwegziehen. Es gibt keine klare Trennung zwischen den Modulen, wodurch es schwer fällt, die Daten und deren Beziehungen auf Anhieb zu verstehen. • Tabellen wie Rechnungspositionen, Auftragspositionen, Angebotspositionen speichern ähnliche Daten, aber in unterschiedlichen Kontexten. Die Beziehungen zwischen diesen Tabellen sind nicht sofort erkennbar und erschweren die Nachvollziehbarkeit.
-
Fehlende Modularität • Es fehlt an Modularität. Zentrale Tabellen wie Kunden, Aufträge und Rechnungen sind nicht klar als Anker definiert. Sie erscheinen in verschiedenen Kontexten ohne eine erkennbare Struktur. • In einer gut strukturierten Datenbank wären diese Tabellen als Anker definiert und in verschiedene Module eingebunden. Diese fehlende Trennung der Module führt zu einem System, das schwer zu pflegen und zu erweitern ist.
-
Wartbarkeit und Erweiterbarkeit • Die Struktur erschwert es, neue Funktionen hinzuzufügen oder bestehende Funktionen zu ändern, ohne die gesamte Datenbankstruktur zu überprüfen. Änderungen an einer Tabelle können unerwünschte Auswirkungen auf viele andere Tabellen haben. • Das Anker-Bojen-Prinzip sorgt durch die Trennung der Module dafür, dass Änderungen in einem Modul nur minimale Auswirkungen auf andere Module haben. Dies macht die Wartung und Erweiterung deutlich einfacher.
-
Fehlende klare Rollen für Tabellen • In dieser Struktur übernehmen viele Tabellen gleichzeitig mehrere Rollen. Es gibt keine klare Unterscheidung, welche Tabellen als Anker fungieren und welche als Bojen. Dies führt zu einer verwirrenden und schwer verständlichen Struktur. • Das Anker-Bojen-Prinzip hingegen sorgt dafür, dass jede Tabelle eine klare Rolle hat. Sie kann entweder als Anker (zentrale Datenquelle) oder als Boje (zusätzliche Datenquelle) fungieren, je nach Bedarf. Diese klare Trennung macht die Datenbank nachvollziehbarer und flexibler.
Vergleich: Mitarbeiterzuordnung mit und ohne KI-Unterstützung
In diesem Blog vergleichen wir zwei Ansätze zur automatischen Zuordnung von Mitarbeitern basierend auf Standort und Verfügbarkeit. Der erste Ansatz nutzt eine KI, um die besten Mitarbeiter auszuwählen, während der zweite Ansatz dies mithilfe von reinem PHP realisiert. Beide Methoden liefern wertvolle Ergebnisse, doch sie haben unterschiedliche Vor- und Nachteile. Eines aber gleich vorneweg, KI ist cool, es ist extrem flexibel, treibt aber mich persönlich an den Rand der Verzweiflung. Warum? Übergebe ich 5 mal die gleichen Daten an die KI, z.B. in meiner Anwendung in folgender Form:
testserver.de/php_calen…|Mario,52.5814763,13.3057333,9:30:00,11:00:00,24204|Mario,52.5346344,13.4224666,12:00:00,13:00:00,22664|Philipp,52.5346344,13.4224666,7:00:00,8:00:00,22664|Philipp,52.4702886,13.2930662,13:00:00,14:00:00,24500|David,52.4702886,13.2930662,10:00:00,11:00:00,24531|Jennifer,52.5035525,13.4176949,9:30:00,10:22:30,24542|Philipp,52.5035525,13.4176949,14:00:00,14:52:30,24543|André,52.5035525,13.4176949,7:30:00,8:22:30,24544|Jennifer,52.6053036,13.3540889,11:00:00,12:30:00,24495|Martin,52.5727963,13.4187507,15:00:00,16:00:00,24485
Dann habe ich zu mindesten zwei verschiedene Ergebnisse. Wenn es ganz schlecht läuft, habe ich 5 verschiedene Ergebnisse.
Code-Beispiel 1: Mitarbeiterzuordnung ohne KI Der folgende PHP-Code sortiert und bewertet Mitarbeiter basierend auf ihrer Entfernung, Verfügbarkeit und Priorität.
$fields[0],
'lat' => (float)$fields[1],
'lng' => (float)$fields[2],
'startTime' => $fields[3],
'endTime' => $fields[4],
'orderNumber' => $fields[5],
];
}
}
if (empty($parsedData)) {
die("Keine gültigen Mitarbeiterdaten empfangen.");
}
$supportRequest = $parsedData[0];
$remainingEmployees = array_slice($parsedData, 1);
// Entfernen des Anforderers aus der Liste
$remainingEmployees = array_filter($remainingEmployees, function ($employee) use ($supportRequest) {
return $employee['name'] !== $supportRequest['name'] ||
$employee['lat'] !== $supportRequest['lat'] ||
$employee['lng'] !== $supportRequest['lng'];
});
// Entfernung und Priorität berechnen
foreach ($remainingEmployees as &$employee) {
$employee['distance'] = round(haversine(
$supportRequest['lat'], $supportRequest['lng'],
$employee['lat'], $employee['lng']
), 2);
$timeToReach = strtotime($supportRequest['startTime']) - strtotime($employee['endTime']);
$timeToWait = strtotime($employee['startTime']) - strtotime($supportRequest['endTime']);
if ($employee['distance'] <= 5 && $timeToReach >= 0 && $timeToReach <= 3600) {
$employee['priority'] = "high";
} elseif ($employee['distance'] <= 10) {
$employee['priority'] = "medium";
} else {
$employee['priority'] = "low";
}
$employee['time'] = "{$employee['startTime']} - {$employee['endTime']}";
}
usort($remainingEmployees, function ($a, $b) {
$priorityOrder = ['high' => 1, 'medium' => 2, 'low' => 3];
return $priorityOrder[$a['priority']] <=> $priorityOrder[$b['priority']];
});
$analysisResult = $remainingEmployees;
?>
Vor- und Nachteile
Vorteile ohne KI: 1. Kosten: Keine Abhängigkeit von KI-Diensten wie GPT-4 reduziert die laufenden Kosten erheblich. 2. Kontrolle: Logik und Priorisierungsregeln können exakt definiert und angepasst werden. 3. Performance: Direkte Verarbeitung auf dem Server führt zu schnelleren Ergebnissen.
Nachteile ohne KI: 1. Flexibilität: Änderungen in den Anforderungen erfordern Anpassungen im Code. 2. Komplexität: Erstellen neuer Algorithmen für komplexere Szenarien erfordert Zeit und Fachwissen.
Code-Beispiel 2: Mitarbeiterzuordnung mit KI Hier wird eine KI verwendet, um Mitarbeiter basierend auf Standort und Verfügbarkeit zu priorisieren. Der PHP-Code sendet die Daten an eine KI-API und verarbeitet die Antwort.
Mitarbeiterzuordnung: Ein PHP-basiertes Tool zur OptimierungVor- und Nachteile
Vorteile mit KI: 1. Flexibilität: Anpassungen an den Anforderungen können durch Änderungen der Anweisungen an die KI erfolgen. Dies kann sogar vom Kunden durchgeführt werden wenn z.B. die Anforderungen in FileMaker definiert werden und dann an die KI gesendet werden. 2. Intelligenz: Komplexere Logiken und Datenmuster können leichter berücksichtigt werden.
Nachteile mit KI: 1. Kosten: Jeder API-Aufruf verursacht Kosten, die sich bei häufiger Nutzung summieren können. 2. Abhängigkeit: Funktionalität hängt von der Verfügbarkeit des KI-Dienstes ab. 3. Performance: Zusätzliche Latenz durch API-Aufrufe.
Fazit
Beide Ansätze haben ihre Berechtigung. Der KI-gestützte Ansatz eignet sich für dynamische und komplexe Anforderungen, während die reine PHP-Lösung ideal für festgelegte und kostenbewusste Szenarien ist.
Welcher Ansatz für dich geeignet ist, hängt von deinen spezifischen Anforderungen und Prioritäten ab. Für mich ist nach dem Test klar, die KI werde ich integrieren, aber nur bei extrem komplexen Prozessen. Gedanklich gehe ich dann in die Richtung, Komplette Tagesplanung für ein Team aus z.B. 10-15 Mitarbeitern mit 30-40 Einsätzen in einem Stadtgebiet verstreut.

Mitarbeiterzuordnung: Ein PHP-basiertes Tool zur Visualisierung und Priorisierung
Dieses Projekt kombiniert PHP, die Haversine-Formel und die Google Maps API, um die besten Mitarbeiter für einen Unterstützungsantrag basierend auf Standort und Verfügbarkeit auszuwählen. Das Ergebnis wird auf einer interaktiven Karte dargestellt, und eine Mitarbeiterliste zeigt alle relevanten Details wie Entfernung und Priorität. Der Grund, viele Mitarbeiter sind bei unterschiedlichen Kunden im Einsatz. Es kann aber notwendig sein, das ein zweiter oder dritter Mitarbeiter für diesen Einsatz benötigt werden. Schwierig die Mitarbeiter aus dem Kopf heraus zuordnen zu wollen.
Überblick
Unser Ziel ist es, ein System zu erstellen, das: • Mitarbeiter basierend auf Entfernung und zeitlicher Verfügbarkeit priorisiert. • Standorte auf einer Karte visualisiert. • Überlappende Standorte automatisch verschiebt, um sie sichtbar zu machen. • Eine übersichtliche Mitarbeiterliste generiert.
PHP: Entfernung und Datenverarbeitung
Im folgenden PHP-Skript berechnen wir die Entfernung zwischen Standorten mit der Haversine-Formel, filtern die Mitarbeiter und senden die Daten an eine KI-Analyse.
$fields[0],
'lat' => (float)$fields[1],
'lng' => (float)$fields[2],
'startTime' => $fields[3],
'endTime' => $fields[4],
];
}
}
// Wenn keine gültigen Daten vorhanden sind
if (empty($parsedData)) {
die("Keine gültigen Mitarbeiterdaten empfangen.");
}
// Der Mitarbeiter, der Unterstützung benötigt
$supportRequest = $parsedData[0];
$remainingEmployees = array_slice($parsedData, 1);
// Entfernung berechnen und in das Array hinzufügen
foreach ($remainingEmployees as &$employee) {
$employee['distance'] = round(haversine(
$supportRequest['lat'], $supportRequest['lng'],
$employee['lat'], $employee['lng']
), 2);
}
// Anfrage an KI zur Analyse senden
$payload = [
'supportRequest' => $supportRequest,
'employees' => $remainingEmployees,
];
// Die Anfrage an die OpenAI-API bleibt unverändert und liefert die Ergebnisse
// JSON-Analyse bleibt wie im Skript
?>
Visualisierung mit Google Maps API
Hier zeigen wir, wie die Ergebnisse visualisiert werden, einschließlich der dynamischen Verschiebung überlappender Marker und einer dynamischen Mitarbeiterliste.
<script>
function initMap() {
const map = new google.maps.Map(document.getElementById('map'), {
zoom: 10,
center: { lat: <?php echo $supportRequest['lat']; ?>, lng: <?php echo $supportRequest['lng']; ?> },
});
const employees = <?php echo json_encode($analysisResult); ?>;
// Unterstützungsmarker hinzufügen
new google.maps.Marker({
position: { lat: <?php echo $supportRequest['lat']; ?>, lng: <?php echo $supportRequest['lng']; ?> },
map: map,
title: "Unterstützungsantrag",
});
// Mitarbeiter hinzufügen
const OFFSET_DISTANCE = 0.001;
const seenLocations = new Map();
employees.forEach((employee) => {
let key = `${employee.lat},${employee.lng}`;
if (seenLocations.has(key)) {
const offset = seenLocations.get(key) + 1;
employee.lat += OFFSET_DISTANCE * offset;
employee.lng += OFFSET_DISTANCE * offset;
seenLocations.set(key, offset);
} else {
seenLocations.set(key, 0);
}
new google.maps.Marker({
position: { lat: employee.lat, lng: employee.lng },
map: map,
title: `${employee.name} - ${employee.distance} km`,
});
});
}
window.onload = initMap;
</script>
Was übergeben wir aus FileMaker
https://deine_url.de/ki_calendar.php?data=André,52.5035525,13.4176949,7:30:00,8:22:30|Mario,52.5814763,13.3057333,9:30:00,11:00:00|Mario,52.5346344,13.4224666,12:00:00,13:00:00|,52.5346344,13.4224666,7:00:00,8:00:00|Philipp,52.4702886,13.2930662,13:00:00,14:00:00|David,52.4702886,13.2930662,10:00:00,11:00:00|Jennifer,52.5035525,13.4176949,9:30:00,10:22:30|Philipp,52.5035525,13.4176949,14:00:00,14:52:30|André,52.5035525,13.4176949,7:30:00,8:22:30|Jennifer,52.6053036,13.3540889,11:00:00,12:30:00|Martin,52.5727963,13.4187507,15:00:00,16:00:00
Fazit
Die Rolle der KI in unserem Projekt
Bei diesem Projekt haben wir die GPT-4 API von OpenAI genutzt, eine hochmoderne KI, die auf natürliche Sprachverarbeitung spezialisiert ist. Die KI übernimmt dabei eine entscheidende Rolle:
Aufgaben der KI 1. Analyse der Daten: Die KI wertet die übermittelten Daten aus, einschließlich der Standorte und Verfügbarkeiten der Mitarbeiter, sowie der geforderten Zeitspanne. Sie trifft Entscheidungen, welche Mitarbeiter am besten geeignet sind, basierend auf: • Geografischer Nähe (Entfernung). • Zeitlicher Verfügbarkeit (Überlappung mit der Anforderungszeit). • Priorisierungskriterien. 2. Priorisierung der Mitarbeiter: Die KI sortiert die Mitarbeiter in Prioritätsklassen (hoch, mittel, niedrig), um Entscheidungsprozesse zu erleichtern. Dies hilft besonders bei komplexen Szenarien mit vielen Teilnehmern und unterschiedlichen Anforderungen. 3. Flexible Verarbeitung: Mit der eingebauten Sprachverarbeitungsfähigkeit kann die KI auf benutzerdefinierte Regeln und neue Anforderungen reagieren. Im Falle unseres Projekts wird sichergestellt, dass: • Der Supportanforderer (Mario) nicht als Unterstützer in die Liste aufgenommen wird. • Die Ergebnisse stets im JSON-Format zurückgegeben werden, damit sie direkt weiterverarbeitet werden können.
Warum GPT-4? • Komplexe Entscheidungen: GPT-4 kann nicht nur einfache Regeln anwenden, sondern auch inhaltlich komplexe Daten wie geografische Koordinaten, Zeitfenster und Prioritäten verknüpfen. • Flexibilität: Änderungen in den Anforderungen (z. B. neue Priorisierungsregeln) lassen sich einfach umsetzen, indem wir die KI-Prompts anpassen. • Effizienz: Im Gegensatz zu einer festen Programmierung ermöglicht die KI schnelle Analysen und Rückmeldungen, ohne den PHP-Code manuell anzupassen.
Das Projekt zeigt, wie sich PHP, eine KI-API und Google Maps zu einem leistungsstarken Logistik-Tool kombinieren lassen. Dies ist natürlich nur eine erste Version und verarbeitet nur wenige Daten.

Das neue Jahr läuft an.
Das neue Jahr läuft an.
Das neue Jahr hat begonnen und ich sitze wieder am Rechner. FileMaker über Google Maps API verbinden, Daten sortieren und anzeigen.

Unterschiede zwischen SQL innerhalb von FileMaker und Datenfindung über Referenzen
Was sind Referenzen in FileMaker?
In FileMaker werden Referenzen durch die visuelle Gestaltung der Beziehungsgraphen im Beziehungsdiagramm erstellt. Hier verbindet der Entwickler Tabellen oder Tabellenvorkommen (Table Occurrences, TOs) mithilfe von Schlüsselfeldern. Diese Verbindungen, auch als Referenzen bezeichnet, ermöglichen es, Daten effizient zwischen Tabellen zu suchen, zu filtern und anzuzeigen.
Vorteile von Referenzen in FileMaker: 1. Visuelle Klarheit: • Der Beziehungsgraph bietet eine intuitive Übersicht über die Datenstruktur und die Beziehungen zwischen den Tabellen. Dies ist besonders hilfreich für Teams und neue Entwickler. • Man sieht sofort, welche Tabellen miteinander verbunden sind und wie Daten durch die Beziehungen fließen. 2. Automatische Navigation: • FileMaker ermöglicht es, Daten aus einer referenzierten Tabelle in Layouts, Portalen oder Berechnungen zu verwenden, ohne explizit SQL-Abfragen zu schreiben. • Entwickler können Daten aus mehreren Tabellen mit minimalem Aufwand kombinieren. 3. Einfachheit bei der Fehlerbehebung: • Wenn Daten nicht korrekt angezeigt werden, können Beziehungen im Graphen leicht überprüft und korrigiert werden. • Es ist einfacher, inkorrekte Beziehungen oder Verbindungsprobleme visuell zu identifizieren. 4. Leistungsvorteile: • Referenzen sind optimiert, um Daten aus verknüpften Tabellen schnell abzurufen, besonders wenn Indexe korrekt verwendet werden. • FileMaker sorgt automatisch für die Synchronisierung und Aktualisierung von referenzierten Daten. 5. Komplexitätsmanagement: • Referenzen eignen sich hervorragend für Szenarien, in denen mehrere Tabellen in einer hierarchischen oder many-to-many-Beziehung zueinander stehen.
SQL in FileMaker
SQL wird in FileMaker hauptsächlich über die ExecuteSQL()-Funktion verwendet. Diese Funktion erlaubt es, SELECT-Abfragen auszuführen, um Daten aus Tabellen unabhängig vom Beziehungsgraphen abzurufen.
Vorteile von SQL in FileMaker: 1. Flexibilität: • SQL-Abfragen ermöglichen es, Daten ohne vorher festgelegte Beziehungen im Beziehungsgraphen abzurufen. • Entwickler können komplexe Abfragen mit Joins, Aggregatfunktionen und Bedingungen erstellen, die mit Referenzen schwer umsetzbar wären. 2. Effizienz bei der Datenaggregation: • Wenn Daten aus mehreren Tabellen aggregiert oder gefiltert werden müssen, können SQL-Abfragen dies in einem einzigen Schritt erledigen. • SQL-Abfragen sind ideal für Berichte, die sich auf große Datenmengen beziehen. 3. Reduktion von TOs (Table Occurrences): • Durch die Verwendung von SQL können Entwickler die Anzahl der Tabellenvorkommen im Beziehungsdiagramm reduzieren, was den Graphen übersichtlicher macht. 4. Unabhängigkeit von FileMaker-spezifischen Logiken: • SQL ist ein standardisierter Ansatz, der für Entwickler, die bereits Erfahrung mit relationalen Datenbanken haben, leicht verständlich ist.
Herausforderungen von SQL in FileMaker
Obwohl SQL eine leistungsstarke Funktion in FileMaker ist, gibt es einige Einschränkungen und Fallstricke, die beachtet werden müssen: 1. Tabellen- und Feldnamen: • In FileMaker können Tabellennamen und Feldnamen Leerzeichen, Sonderzeichen und andere unkonventionelle Zeichen enthalten. Das führt dazu, dass diese Namen in SQL-Abfragen in Anführungszeichen gesetzt werden müssen:
SELECT “Name”, “Adresse” FROM “Kunden”; • Es ist eine bewährte Praxis, Feldnamen ohne Leerzeichen und Sonderzeichen zu verwenden, um diese Probleme zu minimieren.
- Fehlendes Feedback: • Die ExecuteSQL()-Funktion gibt keine detaillierten Fehlermeldungen zurück. Wenn eine Abfrage fehlschlägt, erhält man lediglich ein leeres Ergebnis oder ?. • Fehlerbehebung kann dadurch zeitaufwändig sein. 3. Keine Datenbearbeitung: • ExecuteSQL() ist nur zum Lesen von Daten gedacht. Zum Einfügen, Aktualisieren oder Löschen von Daten müssen andere Methoden verwendet werden. 4. Performance bei großen Datenmengen: • Während SQL bei der Aggregation von Daten effizient ist, kann es bei komplexen Abfragen mit vielen Joins in FileMaker zu Performance-Problemen kommen.
Fazit: Referenzen und SQL in FileMaker bieten jeweils einzigartige Stärken, die auf spezifische Anforderungen abgestimmt sind. Referenzen sind ideal für einfache, visuelle Datenoperationen und garantieren eine nahtlose Integration in Layouts und Workflows. SQL hingegen eröffnet erweiterte Möglichkeiten für komplexe Datenabfragen und Berichte. Eine kluge Kombination dieser Ansätze maximiert die Effizienz und Flexibilität in FileMaker-Projekten.

Die zweite Normalform (2NF)
Die Zweite Normalform (2NF) ist ein Konzept in der Datenbanktheorie, das bei der Gestaltung von Datenbanktabellen verwendet wird, um Redundanz und Anomalien in den Daten zu vermeiden. Die 2NF baut auf der ersten Normalform (1NF) auf und stellt sicher, dass Daten in einer Tabelle zusätzlich zu den Anforderungen der 1NF bestimmte weitere Bedingungen erfüllen.
Um die 2NF zu erfüllen, muss eine Tabelle zwei Kriterien erfüllen:
Alle Nichtschlüsselattribute in der Tabelle müssen funktional von einem ganzen Schlüssel (Primärschlüssel) abhängen, nicht nur von einem Teil des Schlüssels. Mit anderen Worten, alle Nichtschlüsselattribute sollten voll funktional von der Gesamtheit des Primärschlüssels abhängen, um Redundanzen und inkonsistente Daten zu vermeiden.
So kann z.B. eine Kontaktdatenbank aus 2 Tabellen bestehen. Daten wie Name, Vorname, Straße, Land usw. Die Telefonnummer steht aber in einer anderen Tabelle. Nun wird der eine oder andere sich fragen, Warum? Ganz einfach. So ist es ja möglich das der Kontakt nicht nur eine Mobil-Nummer und eine Festnetz-Nummer hat, sondern diverse für sein Business zugeschnittenen Telefon-Nummern. Nun will ich doch aber nicht unter meiner Kontakt-Tabelle 20 oder 30 Felder für diverse Telefon-Nummern führen. Also gehen die Telefon-Nummern in eine andere Tabelle. Verbunden werden die Datensätze mit dem Primärschlüssel. In der Praxis wäre dies wahrscheinlich die Kontakt_ID. Jeder Kontakt hat seine eindeutige Kontakt_ID. Jede zum Kontakt gehörende Telefon-Nummer bekommt diese Kontakt_ID zugeordnet. Nun kann ich entweder über einen SQL-Befehl oder in FileMaker über eine Referenz ganz einfach die zum Kontakt gehörenden Nummern anzeigen lassen.
Es dürfen keine teilweisen Abhängigkeiten vorhanden sein, das heißt, Attribute sollten nicht von einem Teil des Schlüssels abhängen, sondern immer vom gesamten Schlüssel.
Wenn eine Tabelle die 2NF nicht erfüllt, kann dies zu Anomalien wie Update-Anomalien (Änderungen führen zu inkonsistenten Daten), Einfüge-Anomalien (Einfügen neuer Daten ist schwierig) und Lösch-Anomalien (Löschen von Daten führt zu unerwartetem Verlust von Informationen) führen.
Um eine Tabelle in die 2NF zu überführen, müssen teilweise abhängige Attribute in separate Tabellen ausgelagert werden, wobei Beziehungen zwischen den Tabellen durch Fremdschlüssel hergestellt werden. Dies verbessert die Datenintegrität und erleichtert das Datenmanagement.
Es ist wichtig zu beachten, dass die Normalisierung von Datenbanken ein komplexer Prozess ist, der sorgfältige Planung und Analyse erfordert, um die optimale Struktur für die Daten zu gewährleisten. Häufig ist der Planungsprozess natürlich bedingt durch Altlasten oder Fehlerhaft aufgebaute Datenbanken Hinfällig. Dann beginnt die Kernkompetenz des Datenbankentwicklers. Daten werden neu strukturiert, aufgeteilt oder aber auch gelöscht.
Ein hervorragendes Instrument dafür ist FileMaker. Über sein mächtiges Import und Export-Tool, seine einzigartige Art über Relationen Daten zu managen, können auch völlig aus der Struktur geratene Datenbanksysteme neu strukturiert, aufgebaut oder aber die Daten neu Organisiert werden.
Normalisierung von Datenbanken
Datenbanken sind ein wesentlicher Bestandteil unseres Alltags, sei es beim Einkaufen, beim Surfen im Internet oder bei der Suche nach einem neuen Job. Oft werden sie aber auch als komplex und schwer verständlich abgestempelt. Dabei ist es gar nicht so schwer, eine eigene Datenbank zu erstellen und zu verwalten. In diesem Blogpost werden wir uns daher einige verschiedene Methoden der Datenbankmodellierung in Filemaker ansehen.
Struktur ist ein wichtiges Konzept in der Filemaker-Datenbankentwicklung. Die richtige Struktur kann Ihre Datenbanken effizienter und einfacher zu verwalten machen. Wenn Sie eine neue Datenbank erstellen, sollten Sie sich Zeit nehmen, um die Struktur sorgfältig zu planen. Dies wird Ihnen helfen, Zeit und Mühe zu sparen, wenn Sie Ihre Datenbanken später verwalten oder ändern müssen.
Deshalb ist bei der Entwicklung die Struktur zu normalisieren.
Normalisieren eines relationalen Datenbankmodells beschreibt die Trennung von Attributen in zusätzliche Relationen (Tabellen) unter Beachtung von Normalisierungsregeln und Normalformen, sodass eine Form entsteht, die keine unnötigen Redundanzen mehr beinhaltet.
In der Regel ist die Dritte Normalform ausreichend, um die perfekte Balance zwischen Redundanz, Performance und Flexibilität für eine Datenbank zu erzielen. Selbstverständlich gibt es auch Sonderfälle, wie zum Beispiel im wissenschaftlichen Bereich, wo eine Datenbank bis zur 5. Normalform normalisiert werden muss.
Im nächsten Blog werde ich auf die verschiedenen Normalformen eingehen.